
Airflow 대그 병렬로 수행하기
Airflow에서 데이터 파이프라인 최적화
데이터 파이프라인을 구축할때 Airflow는 워크플로우를 자동화하여 관리하는데 핵심적이다. 그러나 dag가 복잡해지고 태스크가 많아질수록 성능 최적화와 데이터 흐름 관리에 주의해야한다.
지난 프로젝트 수행 중 youtube api를 통해 데이터를 수집하고 적재하는 파이프라인을 airflow를 통해 관리했는데, 태스크가 순차적으로 수행되는 경우에 전체 태스크를 수행하는데 시간이 너무 오래 걸리는 문제가 있었다. 이런 이슈를 해결하기 위해 dag 병렬 처리와 태스크간 의존성 관리에 대해서 공부해봤다.
DAG 병렬 처리와 Task 간 의존성 관리
병렬 처리
Airflow에서는 DAG 내의 태스크들을 병렬로 처리하여 워크플로우의 성능을 향상시킬 수 있다.
기본적으로 DAG는 태스크 간의 의존 관계를 정의하여 실행 순서를 제어하는데, 서로 의존성이 없는 태스크들은 병렬로 실행될 수 있다.
여기서 의존관계는 >>, << 연산자를 사용하여 설정된다.
예시
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
default_args = {
'start_date': datetime(2024, 10, 1),
'retries': 1,
}
with DAG('parallel_dag', default_args=default_args, schedule_interval='@daily', catchup=False) as dag:
task_1 = BashOperator(
task_id='task_1',
bash_command='echo "Task 1 실행 중..."',
)
task_2 = BashOperator(
task_id='task_2',
bash_command='echo "Task 2 실행 중..."',
)
task_3 = BashOperator(
task_id='task_3',
bash_command='echo "Task 3 실행 중..."',
)
# 병렬로 실행 가능한 태스크들
task_1 >> [task_2, task_3]
위 DAG에서 task_2와 task_3은 task_1이 완료된 후에 동시에 병렬로 실행된다. 이를 통해 각 태스크를 순차적으로 실행하는 것보다 더 빠르게 DAG를 완료할 수 있다.
프로젝트 수행 내용
dag graph
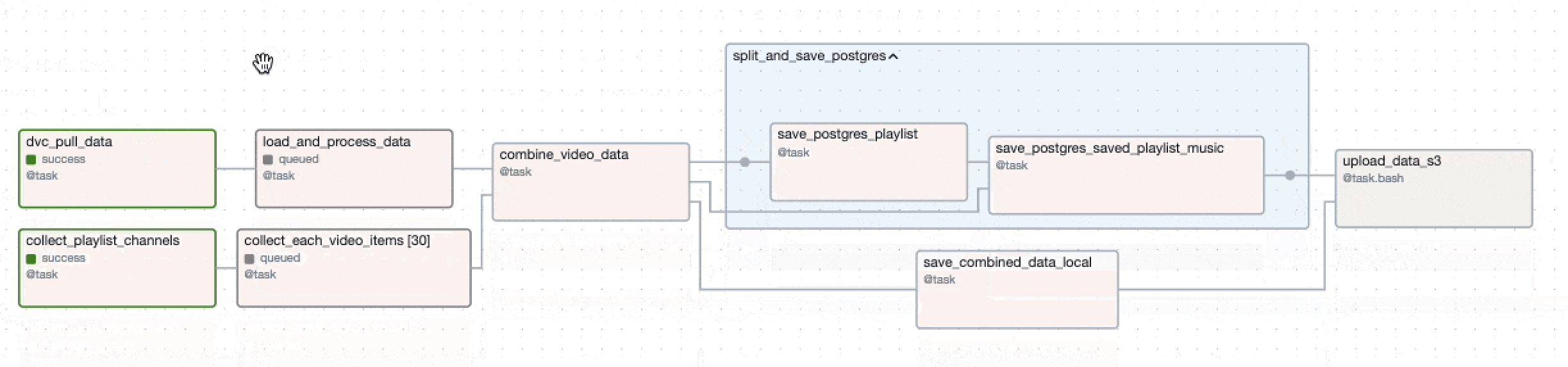
dvc_pull_task >> existing_data
collect_channel_id_task >> video_data_list
[video_data_list, existing_data] >> combined_data >> [save_data_task, split_and_save_postgres_tasks] >> upload_data_s3_task
dag code
def collect_playlist():
@task(task_id="collect_playlist_channels")
def collect_channel_ids():
# 각 채널에 대한 비디오 수집 작업
@task(task_id="collect_each_video_items")
def collect_videos(channel_id: str):
@task(task_id = "dvc_pull_data")
def dvc_pull_data( ... ):
@task(task_id = "load_and_process_data")
def load_and_process_data( ... ):
@task(task_id="combine_video_data")
def combine_video_data(video_data_list, existing_data):
@task(task_id = "save_combined_data_local")
def save_combined_data_local( ... ):
@task.bash(task_id = "upload_data_s3")
def upload_data_s3():
@task_group(group_id = "split_and_save_postgres")
def split_and_save_postgres(json_file):
@task(task_id="save_postgres_playlist")
def save_postgres(json_file):
@task(task_id = "save_postgres_saved_playlist_music")
def save_playlist_music(saved_playlist, json_file):
saved_playlists = save_postgres(json_file)
save_playlist_music(saved_playlist = saved_playlists, json_file = json_file)
# 태스크 순서 설정
collect_channel_id_task = collect_channel_ids()
# 병렬로 각 채널의 비디오를 수집 (expand 사용)
video_data_list = collect_videos.expand(channel_id=collect_channel_id_task)
dvc_pull_task = dvc_pull_data()
existing_data = load_and_process_data()
combined_data = combine_video_data(video_data_list, existing_data)
save_data_task = save_combined_data_local(combined_data)
upload_data_s3_task = upload_data_s3()
split_and_save_postgres_tasks = split_and_save_postgres(combined_data)
dag = collect_playlist()
병렬 처리의 핵심: expand() 사용
이 dag에서 expand() 메서드를 사용해 여러개의 작업을 동시에 실행하도록 설정한 것이 병렬 처리의 핵심이다. 각 유튜브 채널에서 데이터를 수집하는 부분에서 채널 아이디를 수집하고 -> 수집된 아이디에서 영상 정보를 수집하는 부분을 병렬로 처리하도록 하여 처리 성능을 높였다.
expand()의 작동 방식
expand()는 태스크가 리스트나 다른 컬렉션 형태의 데이터를 인자로 받아 각 항목마다 독립적인 인스턴스를 생성해 병렬로 실행할 수 있게 한다. 즉, 하나의 태스크가 여러 번 실행되며, 각각의 실행이 병렬로 처리된다.
Task 간 의존성 관리
Airflow는 태스크 간 의존성을 통해 DAG의 실행 흐름을 제어한다. 의존성을 명확하게 정의하지 않으면 불필요하게 모든 태스크가 순차적으로 실행되거나, 동시에 실행되어야 할 태스크가 지연될 수 있다.
태스크 간 의존성은 >> 또는 << 연산자를 통해 설정하며, 복잡한 의존성 구조에서는 set_downstream() 또는 set_upstream() 메서드를 사용할 수 있다.
task_1.set_downstream([task_2, task_3])
이 코드는 task_1이 완료된 후 task_2와 task_3이 병렬로 실행됨을 의미한다.
Leave a comment