
데이터베이스의 고가용성 패턴
데이터베이스 고가용성 패턴
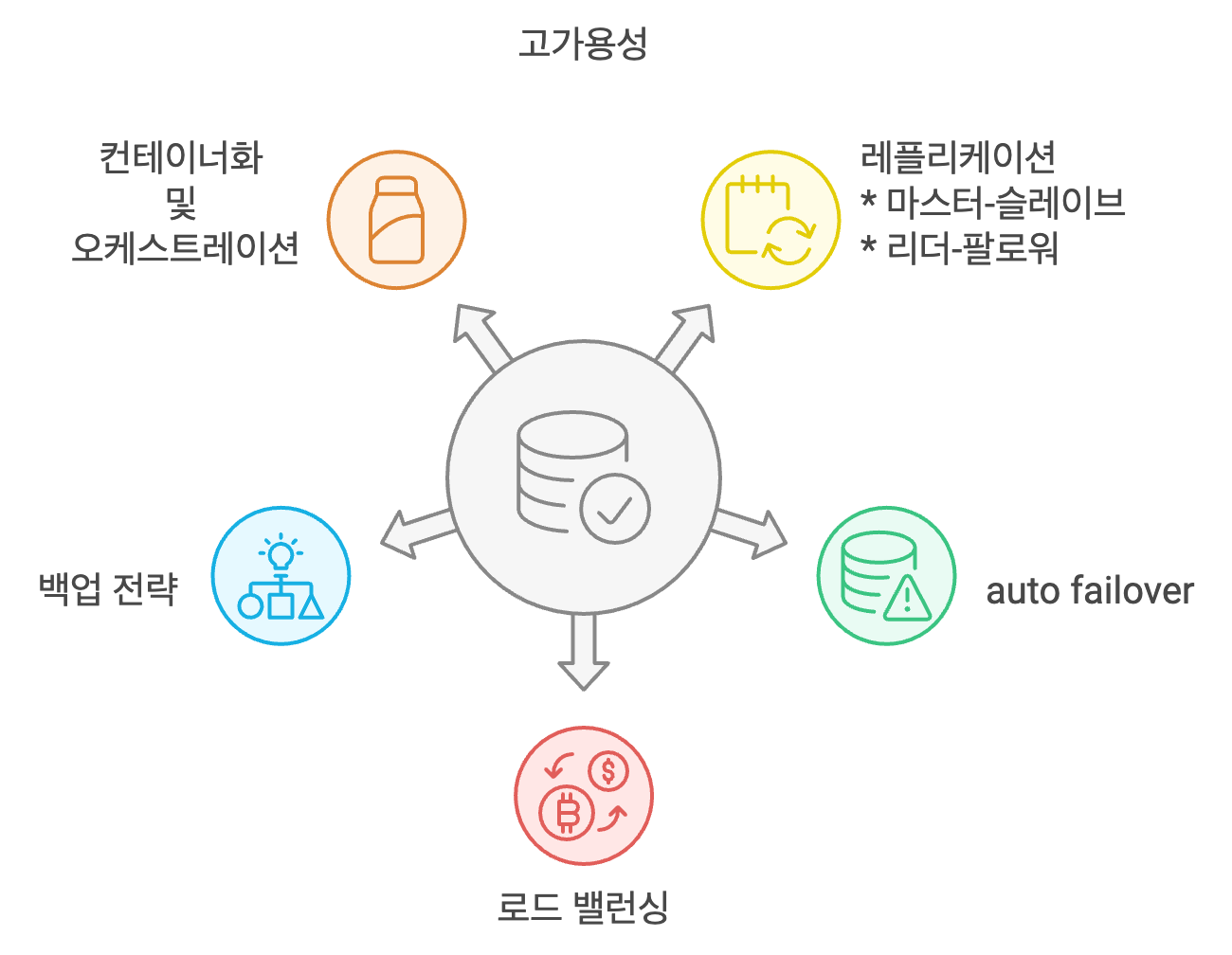
1. 레플리케이션
1) 마스터-슬레이브 구조 (primary-slave 구조)
하나의 마스터가 쓰기 작업을 처리하고 여러 슬레이브가 읽기 작업을 처리. 마스터가 다운되면 슬레이브를 마스터로 승격해서 운영할 수 있지만 이건 failover 방식이고 따로 구성한다.
2) 리더-팔로워 구조
리더가 쓰기 요청을 처리하고 팔로워는 리더로부터 데이터를 복제하여 읽기 요청을 처리. 읽기 부하를 분산시키고, 리더 장애시 팔로워중 하나를 리더로 승격
2. auto failover
장애가 발생햇을때 자동으로 다른 노드로 트래픽을 전환하는 fail over 매커니즘을 구축. 로드 밸런서를 설정하고 db 장애시 빠르게 다른 인스턴스로 전환
3. load balancing
읽기 전용 트래픽을 여러 db 인스턴스에 분산해 부하를 줄이고, 장애시 트래픽을 다른 인스턴스로 전환할 수 있다. 읽기 작업이 많은 경우 다중 읽기 replica 를 사용해 성능과 안정성을 높인다.
4. 백업 및 복구 전략
주기적으로 db를 백업하고 장애시 백업 데이터를 기반으로 빠르게 복구할 수 있는 전략을 마련 postgresql 에서는 wal을 사용해 트랜잭션 로그를 기록하고 복구 시 로그를 사용해 최신 상태로 복구할 수 있다.
5. 컨테이너화 및 오케스트레이션
db 및 기타 서비스를 컨테이너화하고 오케스트레이션 툴을 이용하면 고가용성을 쉽게 구축할 수 있음
failover
마스터 장애시 자동으로 슬레이브를 새로운 마스터로 승격하는 방법
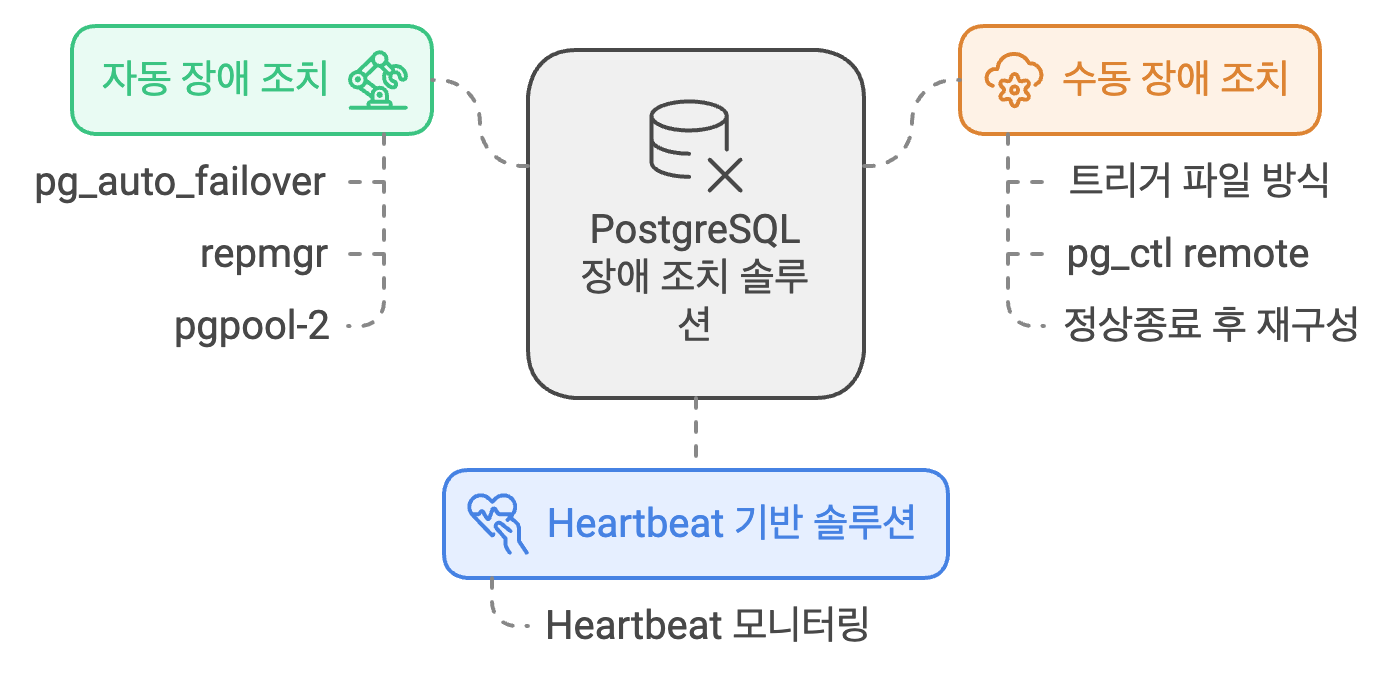
1. auto failover
1) pg_auto_failover
postgresql의 자동 failover를 지원하는 도구로 마스터 장애 발생시 현재의 슬레이브 노드 중에서 가장 최신의 데이터를 가진 노드를 새로운 마스터로 승격
2) repmgr
postgresql에서 마스터-슬레이브 구조의 복제를 관리하는 도구. 자동 fail over를 지원. 마스터가 장애를 겪으면 repmgr이 슬레이브 중 하나를 새로운 마스터로 승격. 다른 슬레이브들은 새로운 마스터와 동기화.
3) pgpool-2
postgresql의 로드밸런싱과 자동 페일오버 기능을 지원하는 미들웨어. 주기적으로 마스터와 슬레이브의 상태를 모니터링하고 장애가 발생하면 페일오버를 해준다. 클러스터 내의 데이터 베이스 인스턴스들을 관리하며 자동으로 장애조치를 수행한다.
2. 수동 failover
1) trigger file 방식
슬레이브 인스턴스가 대기 상태로 있대가 트리거 파일이 생성되면 해당 노드가 즉시 마스터로 승격됨. 직접 파일을 만들어 관리자가 수동으로 failover를 실행할 수 잇게 해줌.
2) pg_ctl remote
postgresql 에서 슬레이브를 수동으로 마스터로 승격하기 위해 pg_ctl remote 명령을 사용. 이 명령을 통해 슬레이브가 복제 모드를 종료하고 마스터 역할을 수행하도록 함. 수동으로 마스터를 지정할 수 있음
3) 정상종료 후 재구성
마스터에 장애가 발생하면 수동으로 마스터를 종료하고 슬레이브를 마스터로 승격한 이후 다른 슬레이브 인스턴스를 재구성하여 동기화하는 방법이 있음
3. Heart beat 기반 솔루션
HA 패턴 중 하트비트 기반 솔루션, pacemaker
고가용성 패턴 적용시 고려사항
- 장애 발생시 얼마나 빠르게 복구할 수 있는지 -> 자동화된 failover, 자동화된 백업 복구 전략
- db 상태를 모니터링하고, 이상이 발생하면 경고를 받을 수 있는지 -> 실시간 모니터링 및 알림 시스템 구축(프로메테우스와 그라파나 등을 활용)
- 데이터 일관성 유지 -> strong consistency, eventual consistency 중 하나를 선택해야함
Leave a comment