
HA 패턴 중 하트비트 기반 솔루션, pacemaker
1. Heartbeat란?
클러스터 내의 서버 간에 정기적인 신호를 주고받으며 서로의 상태를 확인하는 프로토콜. 이 신호가 중단되면 노드 간의 통신이 끊긴 것으로 간주되고, 이를 기반으로 Failover가 트리거됨. 주로 클러스터 관리 시스템에 의해서 관리된다.
주요 역할
- 서버 모니터링: 클러스터 내의 각 서버가 정상적으로 동작하는지 주기적으로 확인
- Failover 트리거: 한 서버가 응답하지 않을 경우, 다른 서버가 이를 감지하고 장애 복구 작업을 시작
2. Heartbeat 기반 솔루션의 핵심 구성 요소
(1) Pacemaker
오픈소스로, 클러스터의 리소스(서비스, 애플리케이션, 데이터베이스 등)을 관리하며 장애 감지 및 failover를 처리한다. corosync 나 heartbeat와 같은 통신 레이어를 통해 각 노드의 상태를 모니터링함.
주요 기능
- failover 관리: 마스터 장애 시 워커를 승격
- 클러스터 리소스 관리: 애플리케이션, 데이터베이스, 파일시스템 등 클러스터의 리소스 관리
(2) Corosync
Corosync는 Pacemaker와 함께 사용되는 클러스터 통신 및 상태 관리 도구. 클러스터 내의 각 노드가 상태 정보를 교환하는 역할을 하며, 클러스터 내에서 장애 발생 시 이를 감지하고 Pacemaker에게 알린다.
주요 기능
- 클러스터 상태 유지: 노드 간 통신을 관리, 노드의 상태를 주기적으로 보고
- heartbeat 구현: 클러스터 내 노드들이 정기적으로 하트비트를 주고받아 장애를 감지하도록 함
- 멀티캐스트/유니캐스트 통신
3. Heartbeat 기반 Failover 동작
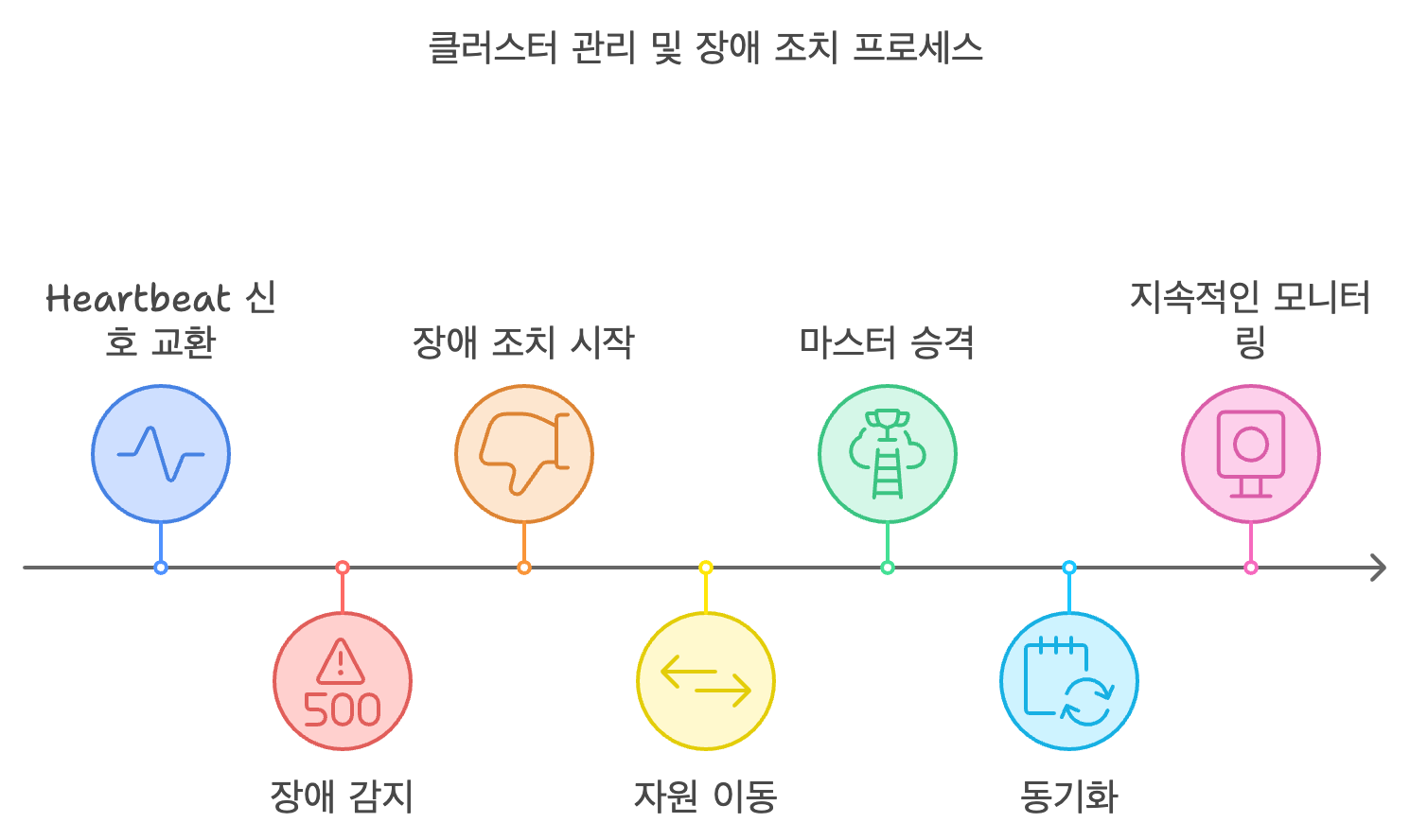
-
노드 간 Heartbeat 신호 주고받기. 노드가 살아있는지 확인
-
장애 감지 특정 노드가 신호에 응답하지 않으면 해당 노드가 장애 상태에 있다고 판단.
-
장애조치 시작 장애가 발생한 노드는 더이상 클러스터의 일부로 인식되지 않음. pacemaker가 이 상태를 감지하여 failover 프로세스를 시작
-
자원 이동 pacemaker는 장애가 발생한 노드에서 실행중인 리소스를 다른 노드로 이동
-
마스터 승격 마스터에 장애가 발생한 경우 pacemaker가 다른 워커를 마스터로 승격시키고 리소스를 재배치함.
-
장애 복구 장애 복구가 완료되면, 새로운 마스터가 정상적으로 작동을 시작하고, 클러스터의 나머지 노드와 동기화.
-
모니터링 계속해서 모니터링
4. 마스터 장애시 선출 방식
pacemaker는 기본적으로 우선순위기반선출방식과 데이터 일관성 기반 선출 방식을 결합하여 마스터 장애시 새로운 노드를 마스터로 선정한다.
1) 우선순위 기반 선출 방식
클러스터내 리소스에 우선순위를 할당할 수 있으며, 마스터 장애시 우선순위가 높은 슬레이브가 새로운 마스터로 승격된다.
2) 데이터 일관성 기반 선출 방식
슬레이브 노드 중에서 가장 최신 데이터를 가진 노드를 새로운 마스터로 승격한다.
- 복제 상태 모니터링 : 각 슬레이브의 복제 상태를 모니터링하며 최신 데이터를 가진 슬레이브를 알고 있다.
- 복제 지연(lag) 고려 : 각 슬레이브의 복제 지연 시간을 고려하여 마스터 장애시 데이터 손실을 최소화할 수 있는 노드를 선택한다.
이 과정에서, 두개의 노드가 동시에 마스터로 승격되는 split-brain 문제가 발생할 수 있다. 예를 들어 네트워크 문제가 발생한 경우에는 일부 노드들이 서로를 잘못된 상태로 판단하여 각각 마스터로 승격된다. 이런 경우에 데이터 일관성 문제가 발생할 수 있는데, 이런 상황에 대비하여 pacemaker는 STONITH(Shoot the other node in the head)기능을 지원한다.
STONITH
장애가 발생한 노드를 물리적으로 종료하거나 네트워크에서 격리하여 클러스터의 안정성을 보장하는 기능
– 참고 자료
Leave a comment