자연어 처리 및 lstm 모델을 바탕으로 플레이리스트 추천하기 : plytube
About
프로젝트 개요
- 플레이리스트 영상 관련 채널의 정보를 수집하여 키워드만으로 플레이리스트 추천 서비스 구축
프로젝트 규모 및 일정
- 팀원 : 2명
- 기간 : 08.12 ~ 09.19
역할
• Youtube API를 활용한 Airflow dag를 구성하여 영상정보 수집 및 파싱 • 플레이리스트 예측 모델링 및 모델 메트릭 수집, 버전 관리 및 CI 시스템 구축 • 모델 서빙 및 CD 시스템 구축 • 예측 서비스를 위한 백엔드 구축
Architecture
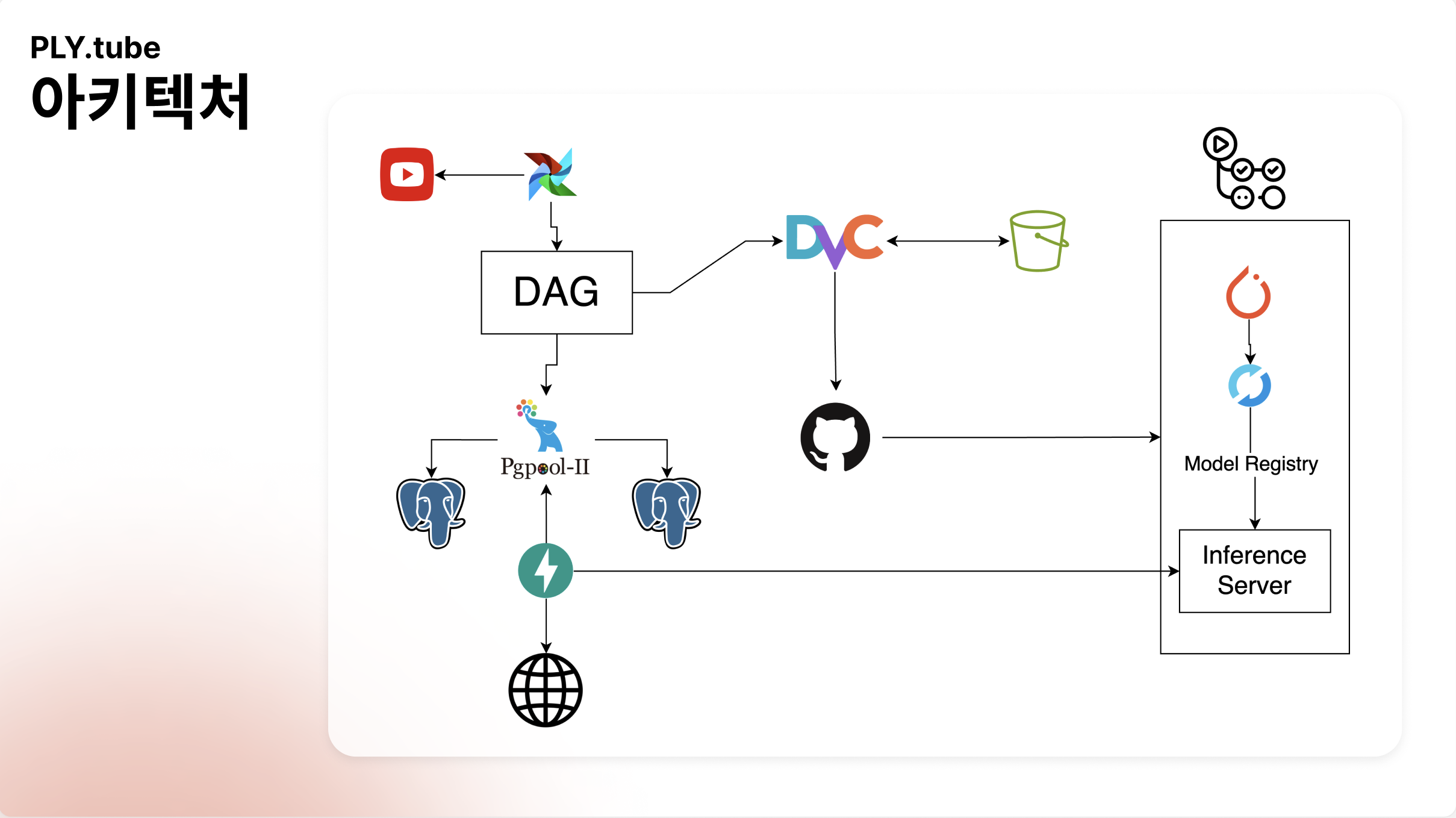
개요
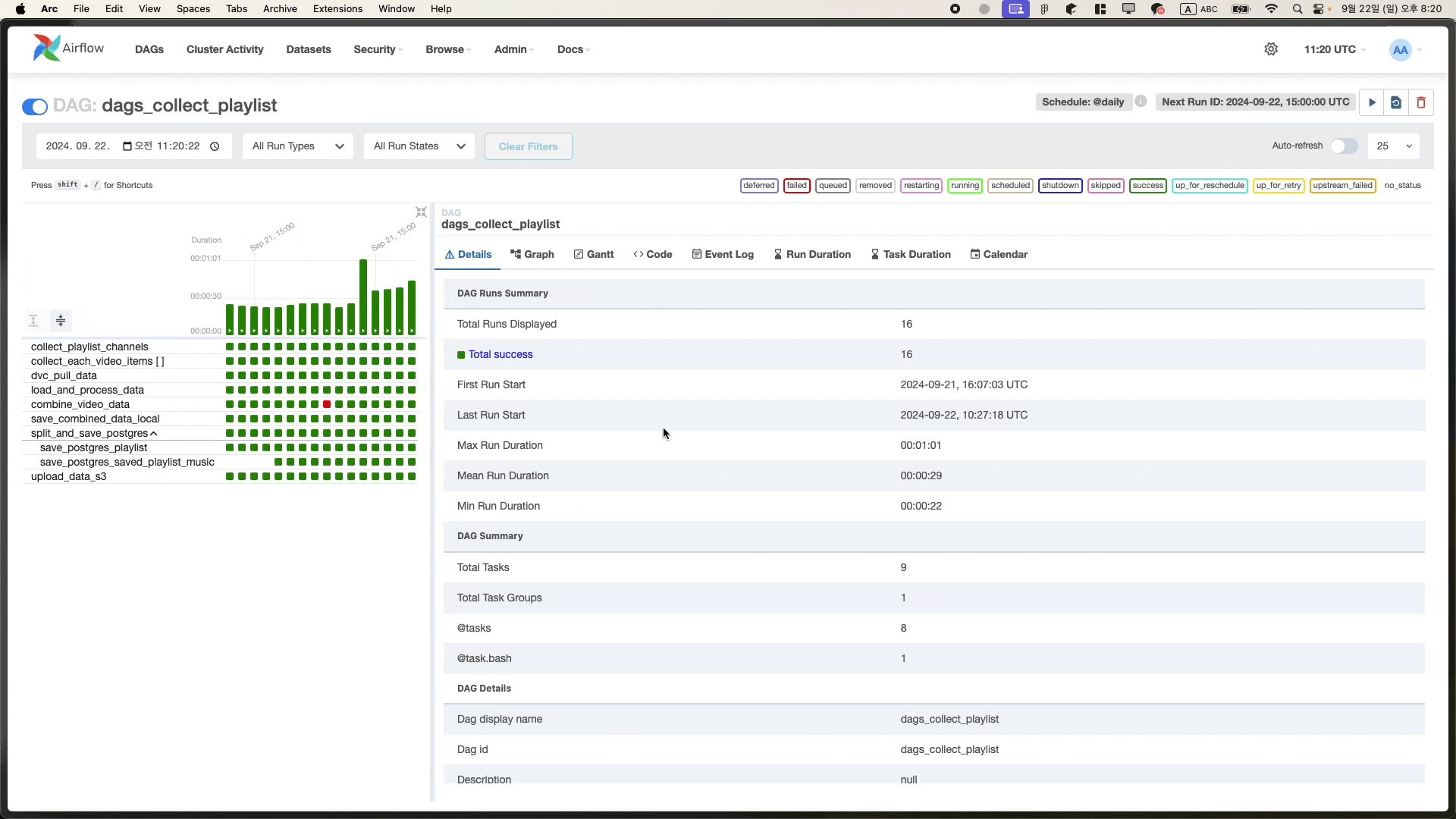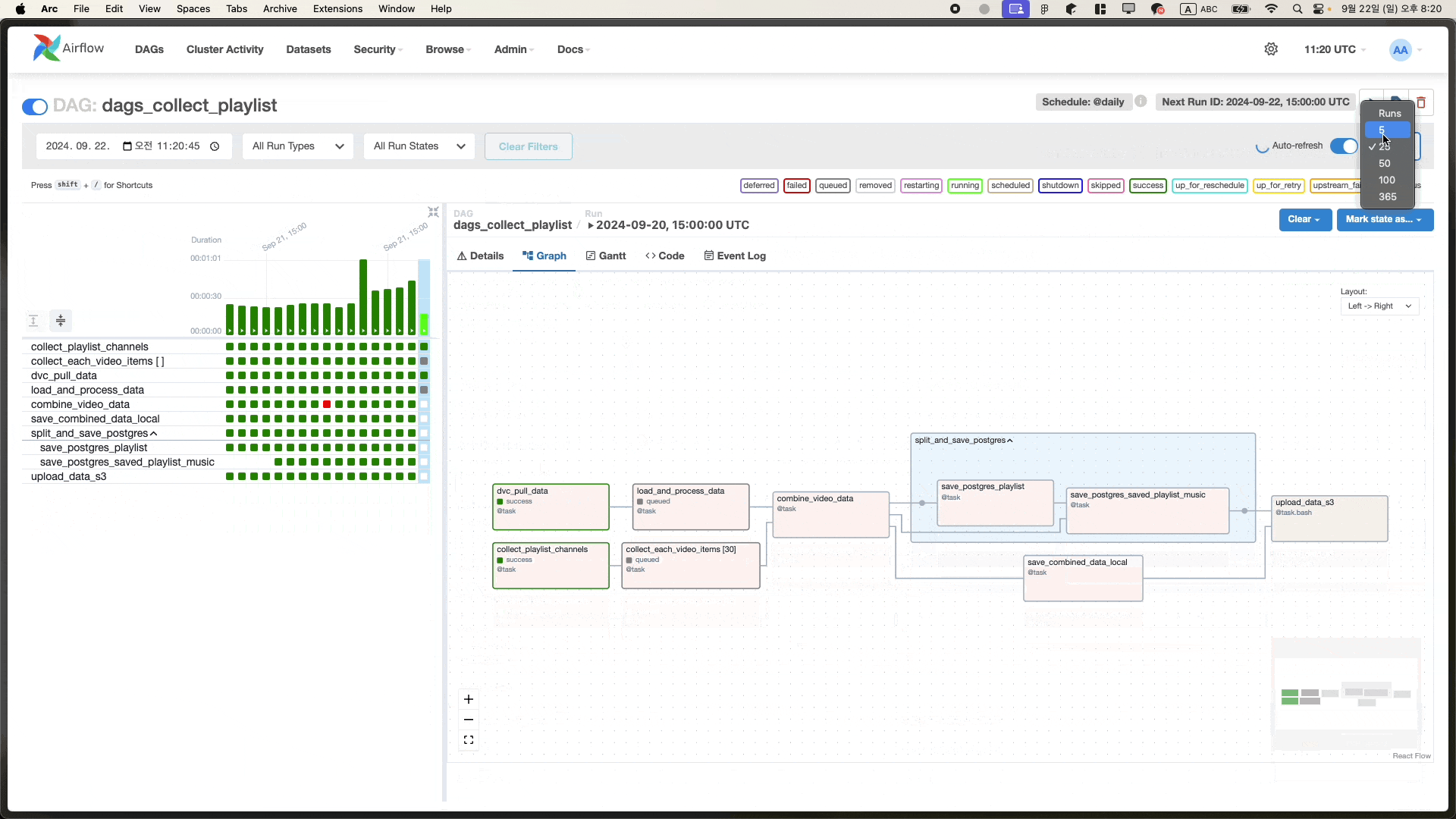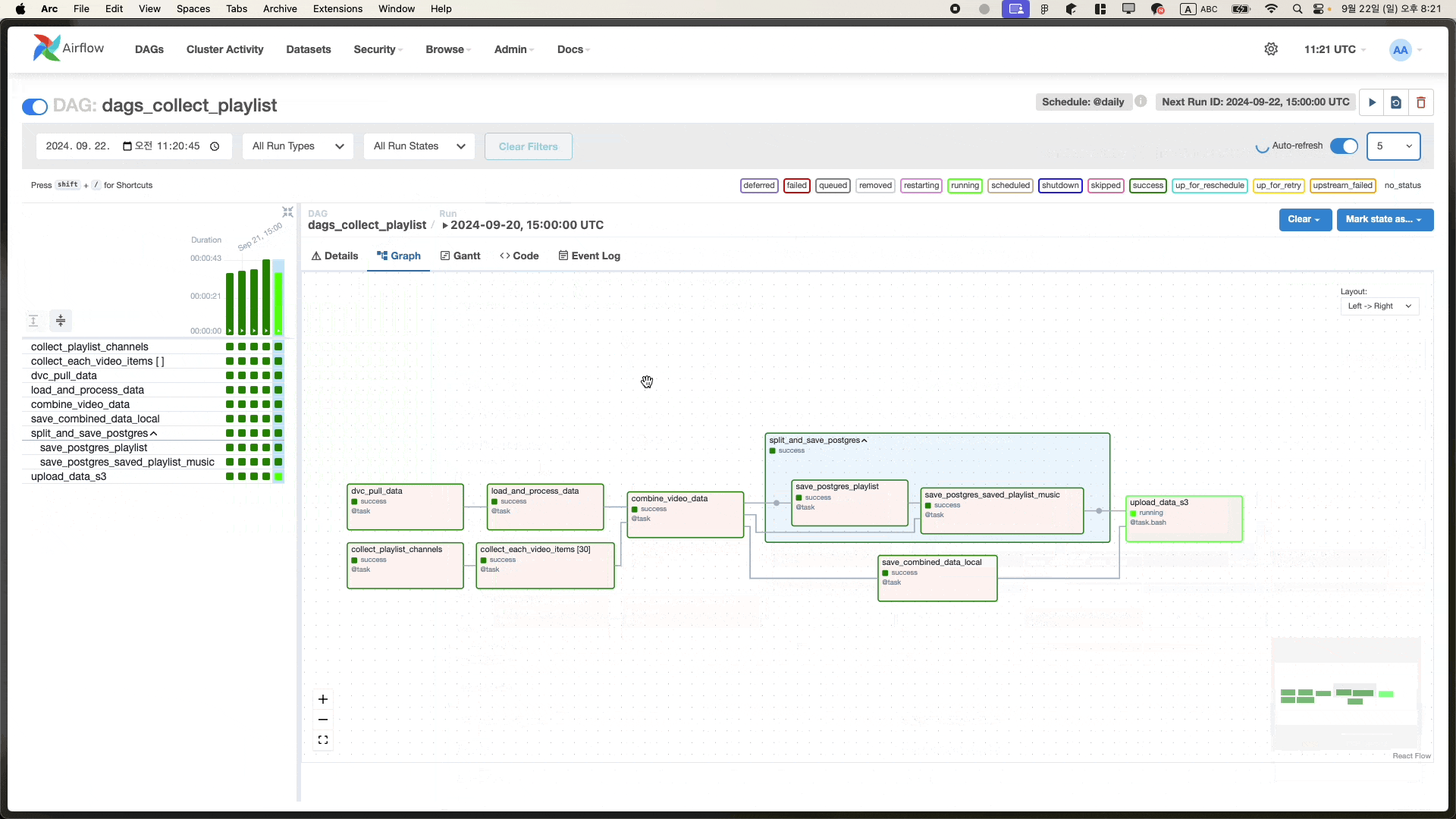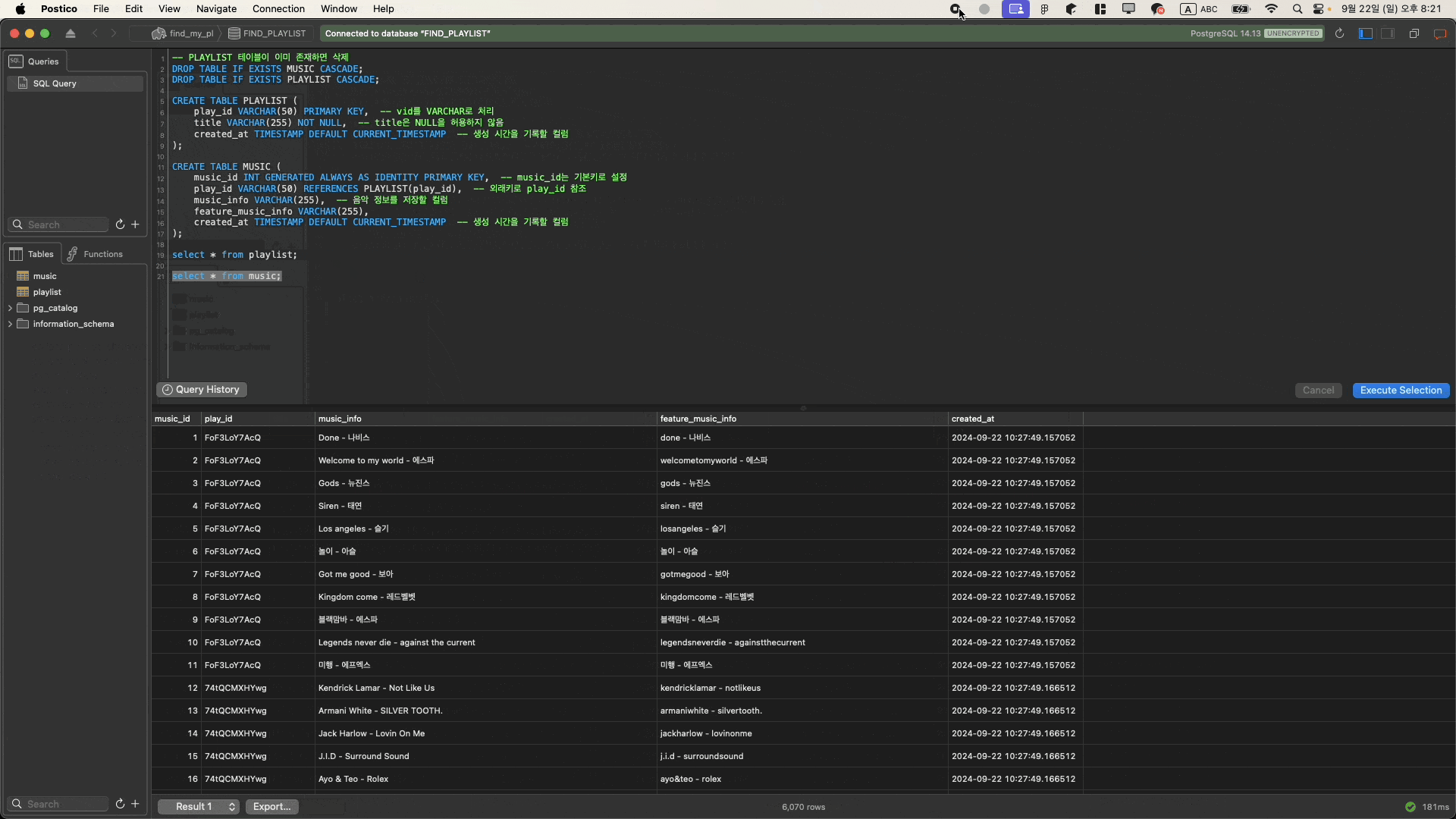
1. YouTube 데이터 수집 및 S3, PostgreSQL에 저장
- Airflow dag를 구성해 ‘playlist, 플리, 플레이리스트’ 키워드를 포함한 채널과 각 채널의 영상 정보를 수집.
- 댓글을 통해 노래정보 파싱해서 json으로 구성해 s3에 저장. 이 파일은 DVC로 버전 관리.
- 채널 및 영상정보는 SQLAlchemy로 PostgreSQL에 저장.
2. 모델 학습 트리거 및 성능 관리
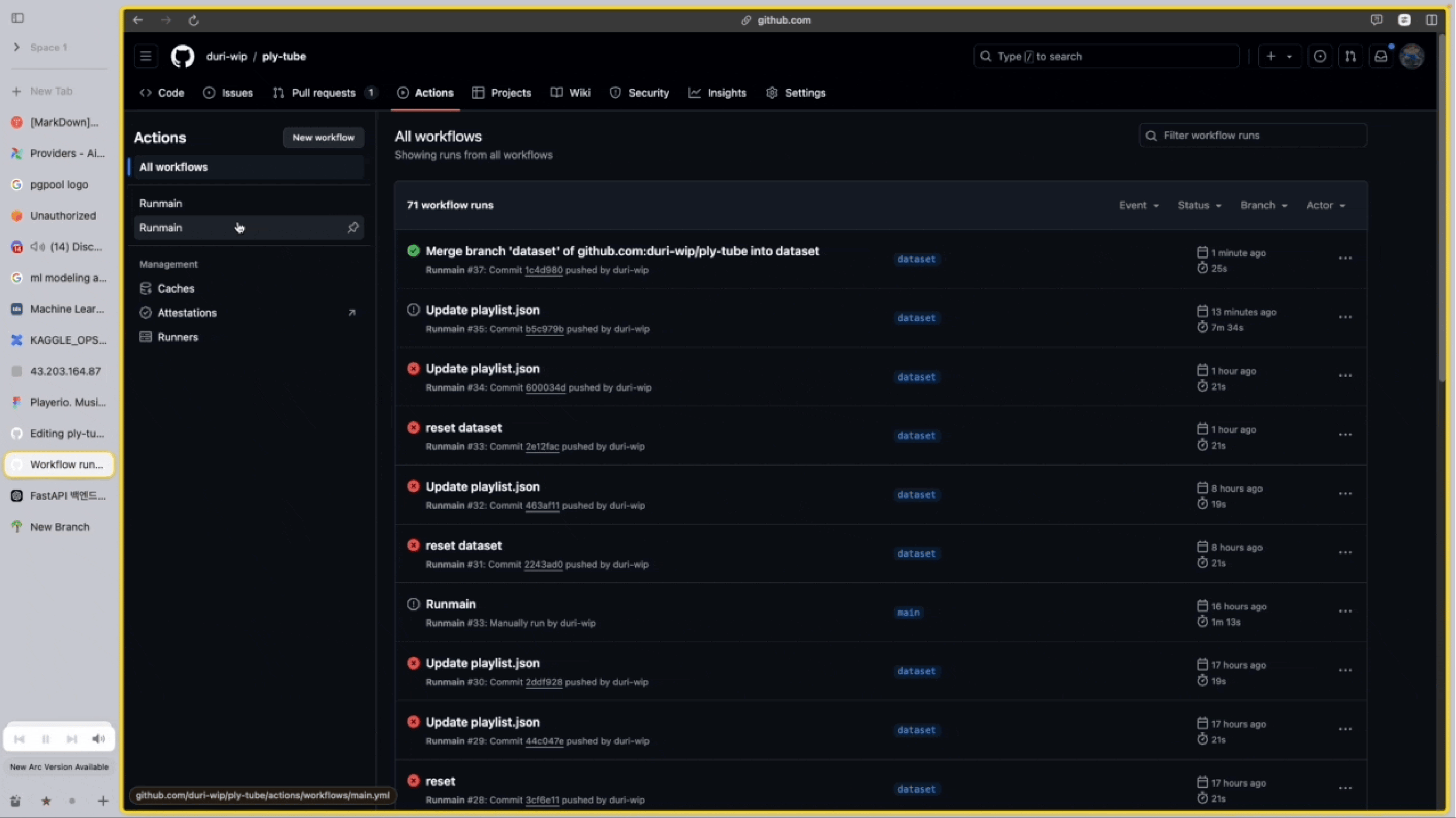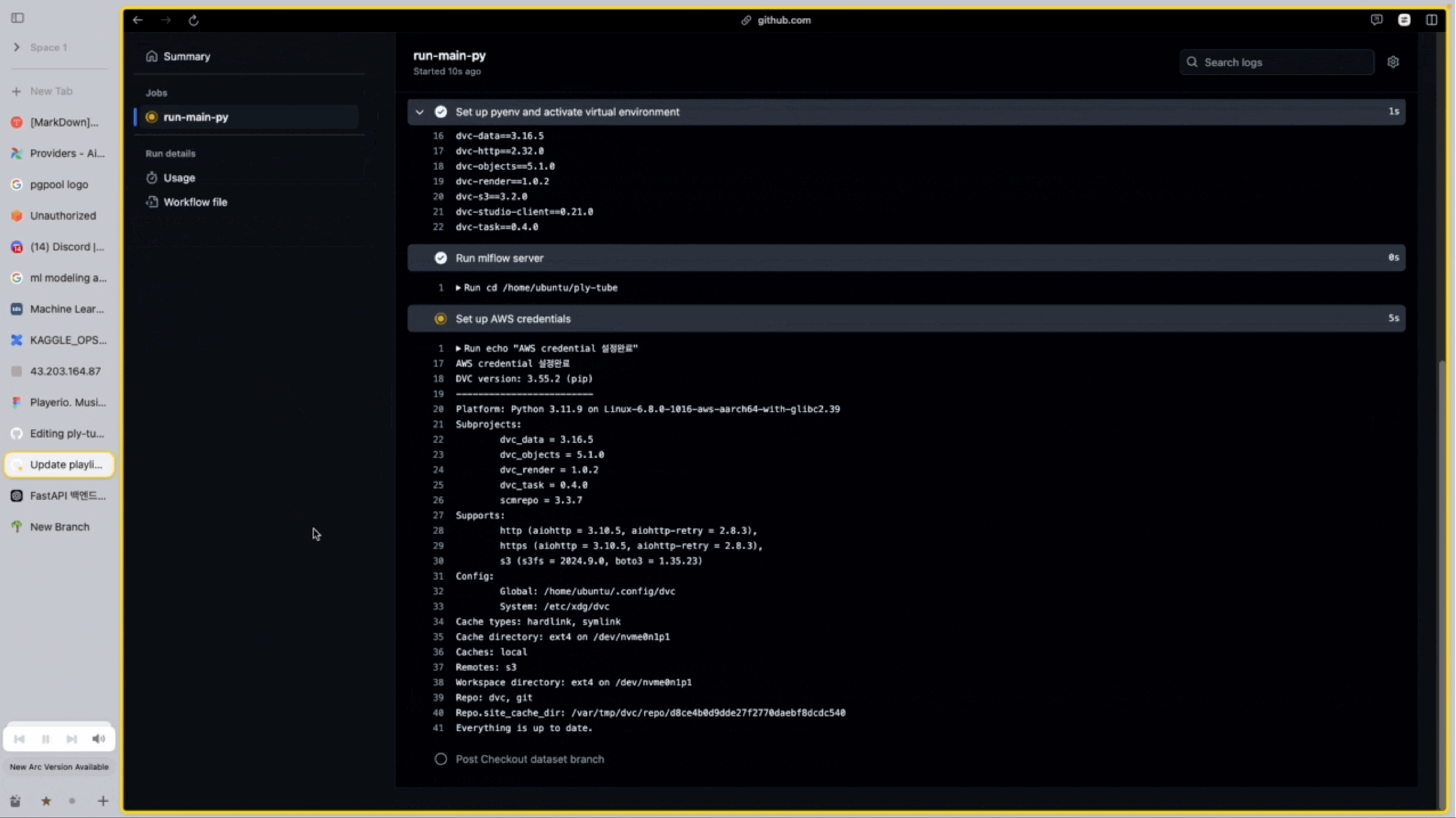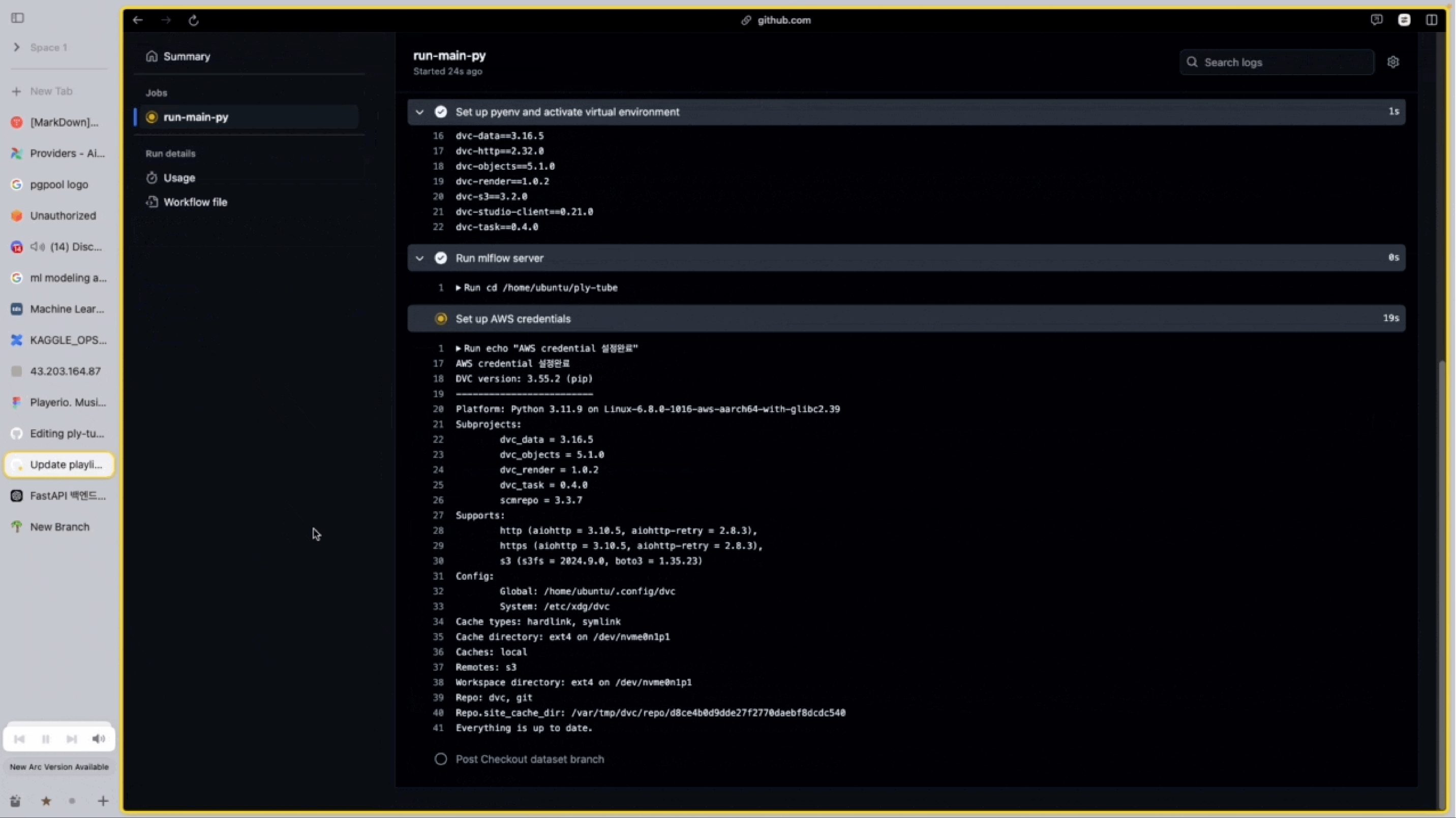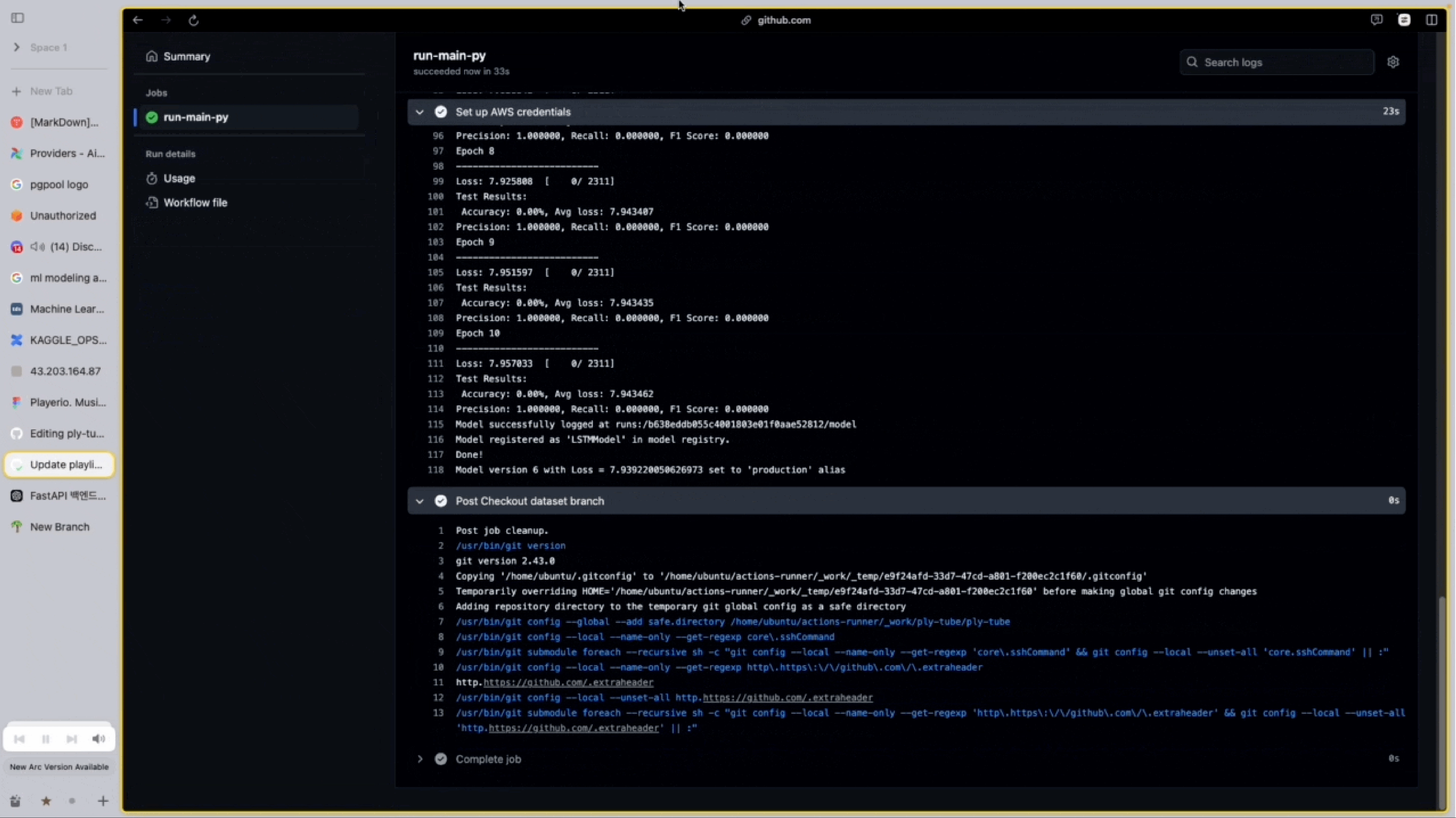
- LSTM 모델로 시계열 기반의 플레이리스트를 예측.
- 새로운 데이터셋은 DVC push를 통해 모델 서버에 트리거 되며, 모델 서버는 DVC pull을 받아 새로운 학습 진행.
- MLflow를 이용해 학습 매개변수와 메트릭을 기록.
3. LSTM 모델 및 추론 서버 운영
- 자동화 파이프라인을 통해 새로운 학습 모델의 성능이 기존 모델보다 좋으면 운영 모델로 교체.
- 사용자가 선택한 값을 모델 구조에 맞게 전처리하고 추론한 예측값을 백엔드 서버에 반환
4. 서비스 운영
- 예측 시 프론트에서 받은 ‘노래’ 또는 ‘가수’ 값을 DB에 저장된 ‘노래-가수’ 또는 ‘가수-노래’ 형식과 매칭하여 이를 모델에 입력값으로 제공.
- 모델은 리스트 형태의 입력과 출력을 처리하되, 예측 시에는 단일 값을 받아 리스트로 반환.