
Spark 애플리케이션
Spark 애플리케이션
스파크 애플리케이션이란?
스파크 애플리케이션은 드라이버와 익스큐터 프로세스로 실행되는 프로그램이다. 클러스터 매니저가 애플리케이션에 필요한 자원을 할당하여 효율적으로 실행된다.
스파크의 기본 아키텍처
스파크는 클러스터에서 작업을 조율하는 프레임워크이다. 클러스터 매니저가 애플리케이션에 자원을 할당하며, 이를 통해 작업을 병렬로 처리한다.
스파크 애플리케이션 구조
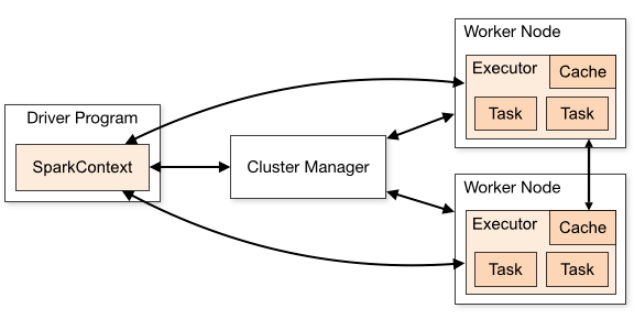
스파크 애플리케이션은 드라이버와 익스큐터로 구성된 마스터-슬레이브 구조이다.
- 드라이버는 스파크 컨텍스트를 생성하고, 클러스터 매니저와 통신해 자원을 관리하며 애플리케이션의 전체 수명주기를 관리한다.
- 익스큐터는 드라이버로부터 작업을 받아 수행하고, 작업 결과를 드라이버에게 보고한다.
파티션
스파크는 데이터를 파티션 단위로 나눠 병렬로 작업을 수행한다. 기본적으로 파티션은 1개로 설정되며, 필요에 따라 조정할 수 있다.
드라이버 실행 모드
- 클라이언트 모드: 클러스터 외부에서 드라이버를 실행한다.
- 클러스터 모드: 클러스터 내에서 드라이버를 실행한다.
스파크 잡의 구성
- 잡(Job): 애플리케이션에서 제출된 작업 단위이다.
- 스테이지(Stage): 잡을 여러 작업 단위로 나눈 것이다.
- 태스크(Task): 각 스테이지 내에서 익스큐터가 처리하는 개별 작업이다. 각 파티션에 대해 병렬로 실행된다.
스파크 애플리케이션 실행하기
실행 방식
스파크는 다양한 언어로 애플리케이션을 실행할 수 있는 스크립트를 제공한다. 각 스크립트는 스파크의 bin 디렉토리에 있다.
cd /usr/local/spark/bin
# bin 디렉토리 실행 파일 목록
-rwxr-xr-x 1 root root 1099 Nov 16 2016 beeline
-rw-r--r-- 1 root root 2143 Nov 16 2016 load-spark-env.sh
-rwxr-xr-x 1 root root 3265 Nov 16 2016 pyspark
-rwxr-xr-x 1 root root 1040 Nov 16 2016 run-example
-rwxr-xr-x 1 root root 3126 Nov 16 2016 spark-class
-rwxr-xr-x 1 root root 1049 Nov 16 2016 sparkR
-rwxr-xr-x 1 root root 3026 Nov 16 2016 spark-shell
-rwxr-xr-x 1 root root 1075 Nov 16 2016 spark-sql
-rwxr-xr-x 1 root root 1050 Nov 16 2016 spark-submit
...
spark-shell: 대화형 쉘로 Spark 코드를 실행한다.pyspark: PySpark 인터프리터로 Python 코드를 실행한다.spark-submit: 클러스터에 애플리케이션을 제출하여 실행한다.
스파크 동작 방식
스파크는 논리적 실행 계획을 작성한 후, 이를 최적화하여 물리적 실행 계획으로 변환한다.
1. 논리적 실행 계획
사용자가 작성한 쿼리나 변환을 바탕으로 생성되는 초기 계획이다. 이 단계에서는 데이터를 어떻게 처리할지 고수준에서 결정한다.
주요 특징
- 변환의 추상적 표현: 논리적 실행 계획은 RDD, 데이터프레임, 데이터셋에 적용된 변환(
filter,map,join등)을 추상적으로 표현한다. - 지연 실행: 사용자가 변환을 호출할 때 즉시 실행되지 않고, 최종 액션이 호출될 때까지 논리적 실행 계획만을 생성한다.
- DAG 생성: 논리적 실행 계획은 DAG(방향성 비순환 그래프)로 구성되며, 데이터의 흐름을 표현한다.
2. 물리적 실행 계획
논리적 실행 계획을 실제 실행할 수 있는 작업으로 변환한 것이다. 클러스터 자원, 데이터 위치, 네트워크 비용 등을 고려해 최적화되며, 데이터를 분산 처리할 방법을 결정한다.
주요 특징
- 클러스터 자원 고려: 물리적 실행 계획은 각 노드에서 연산이 어떻게 수행될지 구체화한다.
- 태스크로 분할: 잡을 스테이지로, 각 스테이지를 여러 태스크로 분할한다.
최적화 과정
- 교환(Shuffle) 최적화: 데이터를 네트워크를 통해 이동시키는 작업의 비용을 최소화한다.
- 파티셔닝 최적화: 데이터를 최적의 파티션으로 나눠 병렬 처리 성능을 극대화한다.
- 병렬 처리 최적화: 스테이지의 태스크를 여러 노드에서 병렬로 실행하여 처리한다.
df = spark.read.csv("data.csv") # 데이터 읽기
filtered_df = df.filter(df.age > 30) # 필터링 변환
selected_df = filtered_df.select("name", "age") # 선택 변환
selected_df.show() # 액션 호출
위 코드는 filter와 select 변환이 적용된 논리적 실행 계획을 만든다. show() 액션을 호출할 때까지 실제로 실행되지 않지만, 이 시점에 논리적 실행 계획이 DAG로 구성된다.
이 예시에서 write.csv가 액션으로 호출되면, 스파크는 물리적 실행 계획을 수립하고 데이터를 병렬로 처리한다. 이 과정에서 Catalyst Optimizer는 최적의 태스크와 스테이지로 변환 작업을 나누고, 각 워커 노드에 태스크를 할당한다.
Catalyst Optimizer의 역할
Catalyst Optimizer는 스파크의 쿼리 최적화 엔진으로, 논리적 실행 계획을 분석해 물리적 실행 계획으로 변환하는 과정에서 최적화를 수행한다. 주요 최적화는 다음과 같다:
- 프로젝션 푸시다운: 필요 없는 열을 제거해 메모리와 I/O 비용을 줄인다.
- 필터 푸시다운: 필터링 작업을 데이터 소스에 가까운 단계에서 수행해 불필요한 데이터를 줄인다.
- 연산 재배치: 연산 순서를 재배열해 네트워크 전송을 최소화하고 중복 계산을 피한다.
Leave a comment