
실시간 데이터 처리와 Spark
실시간 데이터 처리와 Spark
실시간 데이터란 무엇일까?
실시간 데이터는 데이터를 수집하고 처리하는 시간을 기준으로 빠르게 처리되는 데이터를 의미한다. 실시간 데이터는 처리 시간에 따라 분류할 수 있다.
실시간의 분류
| 분류 | 지연 정도 | 예시 |
|---|---|---|
| Hard | 수 마이크로초 ~ 수 밀리초 | 심박조율기, ABS 브레이크 시스템 |
| Soft | 수 밀리초 ~ 수 초 | 항공편 예약 시스템, 주식 시세 서비스 |
| Near | 수 초 ~ 수 분 | 화상 통화, 실시간 로그 분석 대시보드 |
대부분의 시스템은 Hard Realtime이 아닌 Soft나 Near Realtime으로 운영된다. Hard Realtime을 충족하는 것은 기술적으로 어려울 뿐만 아니라, 일반적인 애플리케이션에서는 큰 의미가 없기 때문이다.
따라서, 실시간 데이터는 일반적으로 수 밀리초 ~ 수 분의 지연 시간을 가진 데이터를 의미한다.
실시간 데이터 처리 아키텍처

- 데이터 수집: 웹 브라우저, 모바일 앱, 센서 등 다양한 소스로부터 데이터를 수집.
- 메시지 큐: 수집된 데이터를 메시지 큐에 넣어 저장. (예: Kafka, RabbitMQ)
- 데이터 분석: 메시지 큐로부터 데이터를 받아 실시간으로 분석.
- 결과 저장: 분석 결과를 데이터베이스 또는 파일 시스템에 저장.
- 데이터 제공: 분석된 데이터를 다양한 클라이언트에게 제공.
이 아키텍처에서 Spark는 주로 데이터 분석 단계에서 빠르고 효율적인 실시간 데이터 처리를 담당한다.
실시간 데이터 처리에서 왜 Spark를 사용할까?
Spark의 개념
Spark는 대규모 분산 데이터 처리를 위해 설계된 통합엔진이다. Hadop과 같은 기존의 뷴선 처리시스템에 비해 더 빠른 성능과 다양한 기능을 제공한다.
Spark의 주요 설계 철학과 특징
-
속도
Spark 이전에는 Hadoop의 맵리듀스(MapReduce)가 주로 사용되었으나, 이는 디스크 기반으로 처리되어 속도가 느렸다. Spark는 메모리에서 데이터를 처리해 중간 결과를 저장함으로써 더 빠른 성능을 제공한다. Spark는 물리적 실행 엔진인 텅스텐(Tungsten)을 통해 효율적인 실행 계획을 구성하여 성능을 최적화한다. -
사용의 편리성
Spark는 데이터프레임(DataFrame)과 데이터셋(Dataset)과 같은 고수준 API를 제공하여 프로그래머가 분산 환경을 신경 쓰지 않고도 코드를 작성할 수 있게 해준다. RDD라는 저수준 자료구조를 기반으로 간단한 프로그래밍 모델을 지원하며, Python, Scala, Java, R 등 다양한 언어를 지원하여 개발자들이 각자의 언어로 애플리케이션을 작성할 수 있다. -
모듈성
Spark는 다양한 워크로드를 지원하는 모듈을 제공한다. 예를 들어, Spark SQL, Spark Streaming, MLlib, GraphX 등을 통해 배치 처리, 실시간 스트리밍, 머신러닝, 그래프 처리와 같은 다양한 워크로드를 하나의 통합 엔진에서 처리할 수 있다. 이는 다양한 API를 학습할 필요 없이, 하나의 프레임워크 내에서 여러 기능을 사용할 수 있게 해준다. -
확장성
Spark는 다양한 데이터 소스와 파일 포맷을 지원하며, 필요에 따라 확장이 용이하다. 하둡의 HDFS, Amazon S3, Cassandra 등 여러 데이터 저장소에서 데이터를 불러오거나 저장할 수 있다. 또한, 서드파티 패키지의 지원도 풍부하여 추가적인 기능을 쉽게 통합할 수 있다.
=> 결론: Spark는 속도, 사용 편의성, 다양한 컴포넌트 제공 및 확장성 덕분에 실시간 데이터 처리에 매우 적합한 도구!
Spark 컴포넌트 구성
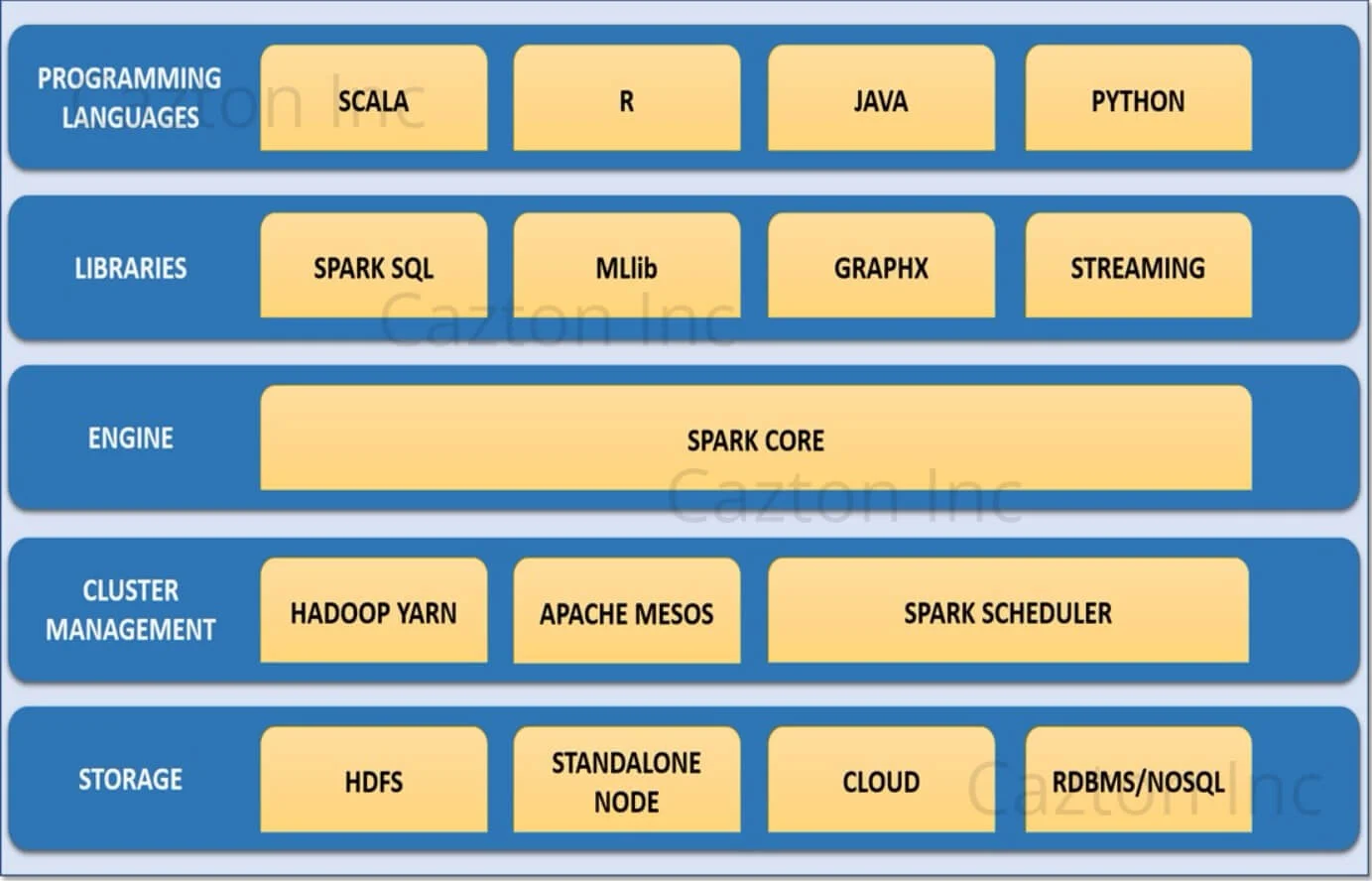
스파크 코어
스파크의 기본 컴포넌트로, 작업 스케줄링, 메모리 관리, 장애 복구, RDD(DataFrame, Dataset) 등의 기능을 제공하여 분산 연산을 처리한다.
스파크 라이브러리
Spark는 다양한 작업을 위한 라이브러리를 공식적으로 제공한다.
-
Spark SQL
SQL을 이용해 RDD, Dataset, DataFrame에 대해 쿼리를 수행하며, Hive Metastore와의 통합도 가능하다. -
Spark Streaming
실시간 데이터 스트림을 처리하며, 스트림 데이터를 작은 배치 단위로 쪼개어 RDD로 처리한다. -
MLlib
머신러닝을 위한 라이브러리로, 분류, 회귀, 클러스터링 등의 알고리즘을 지원하며, 모델 평가 및 외부 데이터 불러오기 등의 기능을 제공한다. -
GraphX
분산형 그래프 처리를 가능하게 해주는 컴포넌트로, 그래프 구조 내에서 각 간선이나 정점에 속성을 부여하여 처리할 수 있다.
클러스터 매니저
Spark는 다양한 클러스터 매니저를 지원합니다. YARN, Mesos, Kubernetes, Standalone 등의 포맷을 사용해 자원 관리를 할 수 있으며, 시스템 환경에 맞는 리소스 매니저를 선택할 수 있다. 스파크 클러스터 매니저 선택 가이드
spark에서 스트리밍 데이터를 처리하는 방법
스파크 스트리밍에 대한 초안을 아래와 같이 작성했습니다:
스파크 스트리밍의 아키텍처
스파크 스트리밍은 마이크로 배칭(micro-batching) 방식을 사용하여 실시간 데이터를 처리한다. 데이터를 작은 시간 단위로 나눠 배치로 묶고, 각 배치를 RDD로 변환하여 스파크의 분산 처리 기능을 활용해 병렬 처리한다.
핵심 구성 요소
- 입력 소스: 실시간 데이터를 제공하는 다양한 소스. (예: Kafka, HDFS, 소켓 등)
- DStream(Discretized Stream): 연속적인 데이터 스트림을 추상화한 객체. 각 시간 단위로 RDD를 생성하며, RDD의 연속체로 생각할 수 있다.
- 처리 엔진: 스파크의 RDD API를 사용하여 변환, 필터링, 집계 등의 작업을 처리한다.
- 출력 소스: 처리된 데이터를 저장하거나, 다른 시스템으로 전송한다. (예: HDFS, 데이터베이스, 대시보드 등)
스파크 스트리밍의 동작 방식
스파크 스트리밍은 실시간 데이터를 일정 시간 간격으로 마이크로 배치로 나눠 처리한다. 예를 들어, 1초 간격으로 들어오는 데이터는 1초 단위의 배치로 나뉘며, 각각이 RDD로 변환되어 처리된다.
마이크로 배칭의 특징
- 작은 배치 단위: 실시간 데이터를 초 단위나 밀리초 단위로 나눠 작은 배치로 처리한다.
- RDD 기반 처리: 각 배치는 RDD로 변환되어 스파크의 분산 처리 엔진을 통해 병렬로 처리된다.
- 높은 처리 성능: 대규모 데이터를 효율적으로 병렬 처리하며, 기존 스파크의 강력한 최적화 기능을 그대로 사용할 수 있다.
스파크 스트리밍의 주요 기능
- 변환(Transformation)
- map, filter, reduceByKey와 같은 기존 스파크의 RDD 변환 기능을 DStream에서도 사용할 수 있다. 각 배치에서 생성된 RDD에 대해 변환을 적용하여 실시간 데이터를 처리한다.
- 집계(Aggregation)
- window 연산을 통해 일정 시간 동안 들어온 데이터를 집계할 수 있다. 예를 들어, 5분간의 데이터를 묶어 집계하거나, 이동 평균을 계산할 수 있다.
- 상태 저장(Stateful Processing)
- updateStateByKey를 사용해 실시간 데이터의 상태를 유지할 수 있다. 이를 통해 장기간에 걸친 데이터의 변화를 추적할 수 있으며, 상태 기반의 스트리밍 처리가 가능하다.
- Fault-tolerance(장애 복구)
- 스파크 스트리밍은 RDD의 특성인 내결함성을 활용해 장애 발생 시에도 데이터를 복구할 수 있다. 데이터가 저장되거나 로그로 남기 때문에 특정 노드가 실패하더라도 다른 노드에서 재실행이 가능하다.
스파크 스트리밍과 구조적 스트리밍
스파크 2.x 이후 등장한 구조적 스트리밍(Structured Streaming)은 기존 스파크 스트리밍의 단점을 개선한 더 높은 수준의 API이다. 구조적 스트리밍은 엔드 투 엔드 정확성을 보장하며, SQL과 DataFrame API를 사용하여 더욱 직관적으로 스트리밍 애플리케이션을 개발할 수 있다.
주요 차이점
- API: 구조적 스트리밍은 DataFrame과 Dataset을 사용하여 더 직관적이고 유연한 API를 제공한다.
- 처리 모델: 스파크 스트리밍은 마이크로 배칭 방식을 사용하지만, 구조적 스트리밍은 지속적인 스트림을 처리하는 방식으로 발전했다.
- 고가용성: 구조적 스트리밍은 Exactly-once 처리 모델을 지원해, 데이터 손실 없이 정확하게 한 번만 처리할 수 있다.
스파크 스트리밍의 활용 예시
- 실시간 로그 처리: 서버 로그 데이터를 실시간으로 수집하여 분석하고, 알림 시스템을 구축할 수 있다.
- 소셜 미디어 데이터 분석: 트위터와 같은 소셜 미디어 데이터를 실시간으로 분석해 트렌드를 파악하거나, 사용자 반응을 실시간으로 모니터링한다.
- IoT 데이터 처리: 센서로부터 수집되는 대규모 데이터를 실시간으로 분석해 기계 상태를 모니터링하거나 예측 분석에 활용한다.
Leave a comment