
Spark 클러스터 구축하기3
지난 포스팅에서 스파크를 각 노드에 설치하고 config 설정을 통해 클러스터를 구성하는 과정을 마쳤다.
그런데 이 방식은 마스터 노드를 명시적으로 지정함으로써 마스터 노드에 장애가 생기면 클러스터 전체를 운영할 수 없게 된다는 치명적인 단점을 가지게 된다.
spark 클러스터의 고가용성
spark는 내장 하둡을 쓰는데 하둡의 yarn을 쓸수는 없을까?
spark3.5.1을 설치하려고 하면 하둡이 있는 버전과 없는 버전(without hadoop)이 있다. 그렇지만 하둡이 없는 버전이라고 해서 하둡이 필요 없는것이 아니다. 사용자가 설정한 하둡을 쓸 수 있는 버전에 불과하다. 하둡이 있는 버전의 스파크를 설치하면 파일 내에 yarn(하둡 에코시스템의 리소스 관리 시스템) 파일이 있게 된다. 그러면 그 yarn을 활용해서 고가용성을 확보할수는 없을까?
결론부터 말하자면 이 프로젝트에서는 그럴 수 없다.
이유 1:
얀을 이용하려면 먼저 하둡 클러스터를 구성해야한다. 그리고 얀을 마스터로 지정해 얀 클러스터에 spark 작업을 spark-submit 을 이용해서 제출해야한다.
그렇지만 이 프로젝트에서는 프로그램을 완전히 구성해서 짜지 않고 주피터랩을 이용해서 실험환경을 구성할 계획이므로 하둡 클러스터를 설계할 수는 없다.
이유 2:
스파크를 설치하면서 함께 설치된 내장 하둡을 클러스터를 구성할때 사용하려면 추가 구성이 필요하다. 이 추가 구성이 없으면(하둡 클러스터를 구성하지 않으면) 독립적인 얀 리소스매니저와 노드매니저를 활성화할 수 없다.
즉 이 프로젝트에서 원하는 것처럼 failover를 구현할 수는 없는것이다.
따라서 주키퍼를 이용해 고가용성을 확보하도록 한다.
1. 모든 노드에 주키퍼 설치하기
sudo apt install zookeeperd
주키퍼 설정
/etc/zookeeper/conf/zoo.cfg파일을 수정한다(기본경로)
#모든 클러스터 노드 리스트 설정
server.1=zookeeper-node-1:2888:3888
server.2=zookeeper-node-2:2888:3888
server.3=zookeeper-node-3:2888:3888
여기서 zookeeper-node-1…에 들어갈 수 있는 정보는 다음과 같다.
- /etc/hosts 에 설정한 이름
- 노드의 ip
/var/share/zookeeper/conf/ 디렉토리 안에 myid 파일을 만들어준다
sudo -i
echo '1' > /var/share/zookeeper/conf/myid
각각의 노드에 대해 맞게 id를 지정해줘야함
방화벽 규칙 설정
2888, 3888, 2181을 주키퍼가 사용할 포트이므로 미리 열어준다.
스파크 마스터 노드는 7077을 사용하므로 이것도 열어준다.
2. 스파크 설정 추가하기
$SPARK_HOME/conf/spark-env.sh에 다음과 같은 설정을 추가한다.
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zookeeper-node-1:2181,zookeeper-node-2:2181,zookeeper-node-3:2181 -Dspark.deploy.zookeeper.dir=/spark"
이때 기존에 worker, master 설정을 한게 있다면 확인하고 삭제해주도록 한다.
3. 실행하기
여기서부터가 복잡한데, 왜 사람들이 이런식으로 클러스터를 구성하지 않는지, k8s나 하둡을 사용하는지 알 수 있는 대목이었다.
1. 각 노드에서 마스터 노드를 실행한다. (모든 노드에서 실행해야함)
$SPARK_HOME/sbin/start-master.sh
그러면 각각의 노드에서 마스터 프로세스가 실행되게 되고, 이 과정에서 주키퍼가 리더를 선출하여 하나의 마스터 노드만 활성 상태로 운영된다. 나머지 선출되지 못한 노드들은 스탠바이 상태가 된다.
2. 어떤 노드가 리더로 선출되었는지 확인하기
주키퍼 명령어 쉘을 이용해서 리더로 선출된 노드의 정보를 확인한다. zkCli.sh에 접속하면 되는데, 이 파일은 보통 /usr/share/zookeeper/bin/ 에 저장되어 있다.
/usr/share/zookeeper/bin/zkCli.sh -server spark01:2181
:::warning log4j:ERROR setFile(null,true) call failed. java.io.FileNotFoundException: /var/log/zookeeper/zookeeper.log (Permission denied) :::
이런 에러가 뜨는 경우에는 log 파일에 접근할 권한이 없어서 그럴 수 있다. 나는 소유자를 확인하고 그 유저로 확인하는 방법으로 해결했다.
sudo -u zookeeper /usr/share/zookeeper/bin/zkCli.sh -server spark01:2181
이 쉘에 접속해서 interactive 방식으로 선출된 리더 정보를 확인한다.
get /spark/master_status
이런식으로 정보가 뜬다.
[zk: spark02:2181(CONNECTED) 0] get /spark/master_status
10.178.0.8
cZxid = 0x300000004
ctime = Mon Oct 28 05:45:10 UTC 2024
mZxid = 0x300000004
mtime = Mon Oct 28 05:45:10 UTC 2024
pZxid = 0x300000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 10
numChildren = 0
3. 리더 이외의 노드에서 스파크 프로세스를 끄고 워커 노드 시작하기
ps -ef |grep spark
로 기존에 마스터 버전으로 켰던 스파크 프로세스의 pid를 확인하고 삭제한다.
$SPARK_HOME/sbin/start-worker.sh spark://<선출된 리더 ip>:7077
선출된 리더 아이피를 가지고 워커 노드를 시작한다.
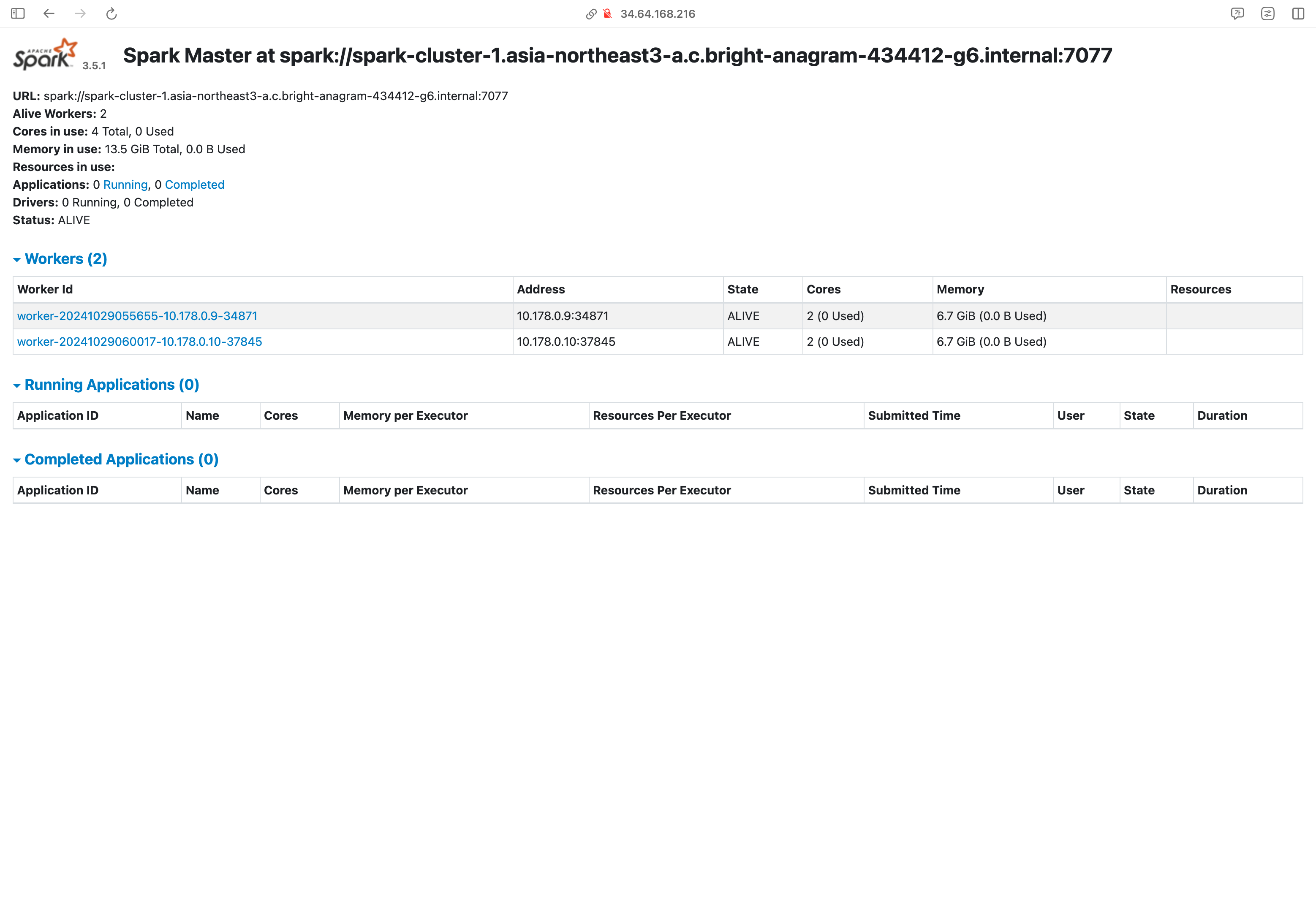
마스터 웹 ui를 확인하면 이렇게 구성된걸 볼 수 있다.
–
리더에 장애가 발생하면 주키퍼가 이를 감지하여 새로운 노드를 리더로 선출한다. ( fail over )
fail back 하는 법 : 장애노드 복구 후 원래 상태로 복귀하기 이러한 설정에서는 fail back이 자동으로 이뤄지지 않는다. 따라서 복구된 노드에서 다시 start-master 쉘을 실행해줘야 클러스터에 노드로 등록된다.
fail back이 자동으로 되지 않는 이유:
- fail back은 복구된 리더가 자동으로 리더 역할을 맡도록 설정해준다.
- 그런데 스파크 고가용성은 안정성을 우선시하기 때문에 이미 안정적으로 운영중인 리더를 교체하지 않는다.
이렇게 매번 수동으로 모든걸 해주기 어렵기 때문에 아무도 이렇게 안하나보다.. 자동화 스크립트를 짜서 그걸 실행하는 방법이 나을것 같다.
4. jupyter lab 실행하기
- 주피터랩을 모든 노드에 설치함
- 주피터랩을 실행할 쉘 파일을 모든 노드에 만들어줌 ```bash #!/bin/bash
pyenv 환경 초기화
export PATH=”$HOME/.pyenv/bin:$PATH” eval “$(pyenv init –path)” eval “$(penv init -)” eval “$(pyenv virtualenv-init -)”
가상환경 활성화
pyenv activate spark
Jupyter Lab 실행
~/.pyenv/versions/spark/bin/jupyter lab –no-browser –port=8888 –ip=0.0.0.0
* 고정적으로 하나의 노드에서 마스터 ip를 찾아서 주피터랩을 실행하도록 하는 쉘을 만듦
```bash
#!/bin/bash
# Zookeeper로부터 현재 마스터 IP 조회
while true; do
master_ip=$(sudo -u zookeeper /usr/share/zookeeper/bin/zkCli.sh -server spark01:2181 get /spark/master_status | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}')
if [ ! -z "$master_ip" ]; then
echo "마스터 IP: $master_ip"
# SSH 터널링 설정 (기존 터널 종료 후 재설정)
pkill -f "ssh -L 8888"
ssh -L 8888:$master_ip:8888 swc@$master_ip -f "~/start_jupyter.sh" &
fi
sleep 50 # 주기적 확인
done
이 쉘을 실행하면 마스터 ip를 찾아서 주피터 랩을 실행해준다. 그러면 이 마스터 ip의 8888번 포트에 들어가 주피터랩에 접근한다.
왜 아무도 이런짓을 안하는지 잘 알수 있었다..
다음 포스팅에서는 드디어 수집을 해보겠다.
Leave a comment