
Spark의 핵심
RDD (Resilient Distributed Dataset)
RDD란 무엇인가?
RDD는 Resilient Distributed Dataset의 약자로, 스파크의 핵심 데이터 구조이다. RDD는 분산 데이터 처리를 위해 설계된 불변성을 가진 파티셔닝된 레코드의 모음이다. RDD는 대규모 데이터를 효율적으로 처리하기 위한 분산형 컬렉션으로, 병렬 처리와 내결함성을 제공한다.
RDD의 등장 배경
Hadoop의 핵심인 MapReduce는 대용량 데이터를 빠르게 처리할 수 있는 프레임워크였다. 하지만 반복 작업(iteration)을 수행할 때마다 중간 결과를 HDFS와 같은 디스크 스토리지를 통해 공유해야 한다는 한계가 있었다. 이로 인해 반복 연산이 많은 작업에서는 성능 저하가 발생했다.
스파크는 이러한 문제를 해결하기 위해 데이터를 메모리(RAM)에 올려서 중간 결과를 저장하고, 반복 작업을 빠르게 처리하는 접근 방식을 선택했다. 하지만 메모리에 데이터를 저장할 경우 장애 복구(Fault Tolerance)가 문제가 되는데, RDD는 불변성과 계보(lineage) 기록 방식을 통해 내결함성을 보장한다.
RDD의 특징
- 불변성 (Immutability): RDD는 생성된 후 수정할 수 없는 불변성을 가진다. 데이터가 변경될 경우 새로운 RDD가 생성된다. 이로 인해 병렬 처리에서 안전한 연산이 가능하다.
- 분산 처리 (Distributed Processing): RDD는 여러 파티션으로 나누어져 클러스터의 노드에서 병렬로 처리된다. 이를 통해 대규모 데이터를 빠르게 처리할 수 있다.
- 내결함성 (Fault Tolerance): RDD는 각 데이터의 변환 과정을 기록한 계보(lineage)를 유지한다. 장애가 발생하면 이 계보를 따라 데이터를 복구할 수 있다.
- 지연 실행 (Lazy Evaluation): RDD의 변환 작업은 액션(action)이 호출되기 전까지 실제로 실행되지 않는다. 변환(transformations)은 실행 계획을 세우는 작업이며, 최종 액션이 호출될 때 이 계획이 실행된다.
- 메모리 기반 처리: RDD는 가능한 한 메모리에 데이터를 저장하여 처리한다. 그러나 메모리가 부족할 경우 디스크에 저장할 수 있으며, 이를 통해 스파크는 대규모 데이터를 처리할 수 있다.
RDD의 동작 방식
RDD는 변환과 액션이라는 두 가지 연산으로 이루어진다. 변환은 새로운 RDD를 생성하는 작업이고, 액션은 데이터를 처리하고 최종 결과를 반환하는 작업이다.
-
변환(Transformation): 새로운 RDD를 생성하는 연산이다. 예를 들어,
map,filter,flatMap등이 변환에 해당한다. 변환은 지연 실행되며, 실제 데이터 처리는 액션이 호출될 때 이루어진다. -
액션(Action): 변환으로 생성된 RDD에 대해 실질적인 작업을 수행하고 결과를 반환한다. 예를 들어,
count,collect,saveAsTextFile과 같은 연산이 액션에 해당한다.
지연 실행 (Lazy Execution)
RDD의 중요한 특징 중 하나는 지연 실행이다. 변환 작업은 즉시 실행되지 않고, 액션이 호출될 때까지 모든 변환이 대기 상태에 있다. 스파크는 변환 작업을 통해 실행 계획(Execution Plan) 을 설계하고, 액션이 호출되면 이 계획을 기반으로 변환을 일괄 처리한다.
이점: 지연 실행을 통해 스파크는 전체 데이터 흐름을 최적화할 수 있다. 모든 변환을 미리 실행하지 않기 때문에 불필요한 연산을 줄이고, 최적화된 실행 경로를 설계할 수 있다. 또한, 중간 데이터를 저장하지 않고 필요할 때만 데이터를 처리하기 때문에 메모리 효율이 높다.
넓은 의존성과 좁은 의존성
RDD 변환은 넓은 의존성(wide dependency) 과 좁은 의존성(narrow dependency) 으로 나뉜다.
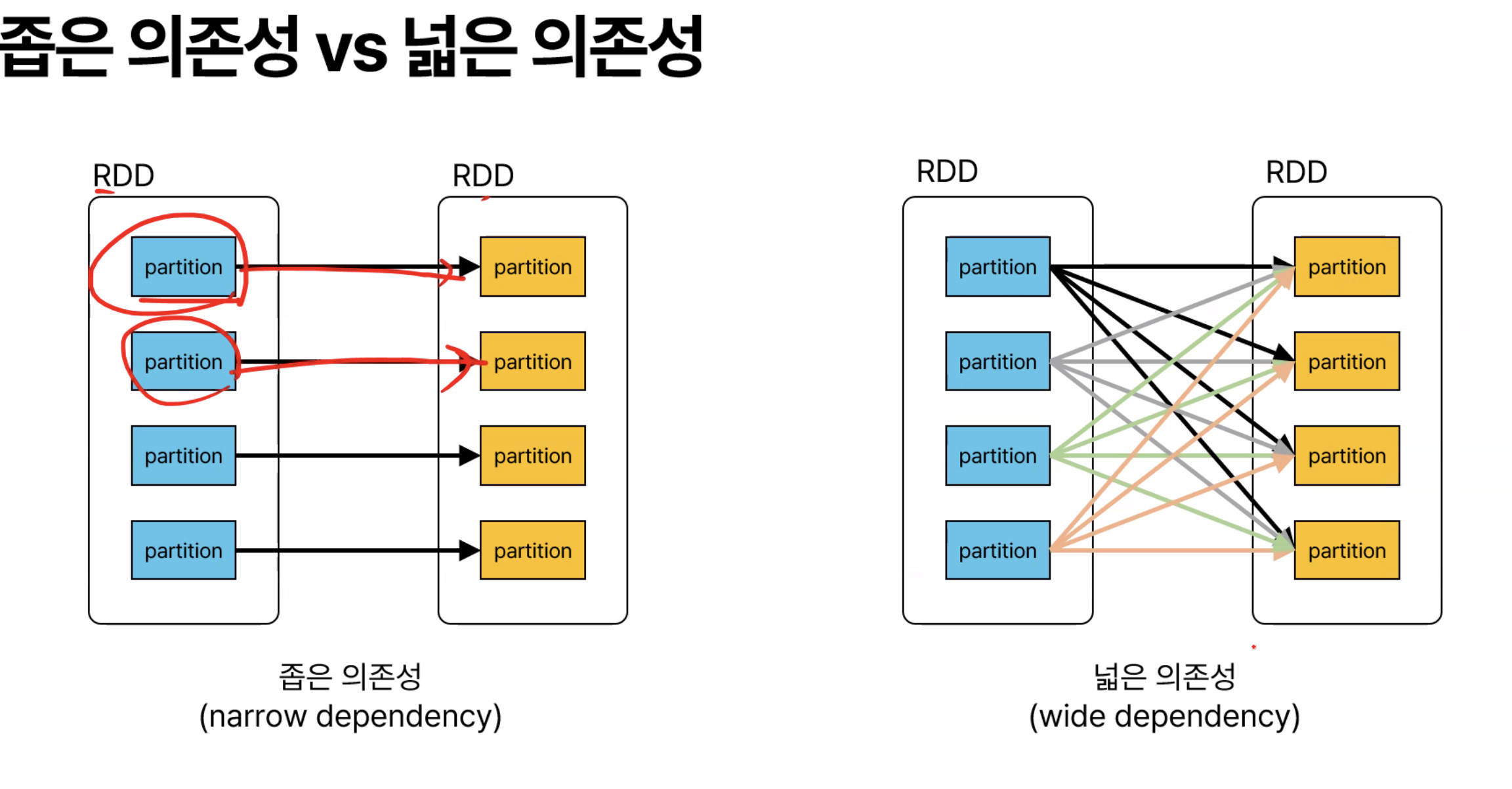
-
좁은 의존성: 하나의 부모 RDD가 여러 자식 RDD로 나뉘지 않고, 하나의 자식 RDD가 하나의 부모 RDD의 일부에만 의존하는 경우이다. 예를 들어,
map이나filter와 같은 변환은 좁은 의존성을 가진다. 이 경우, 각 파티션이 독립적으로 처리되므로 연산이 상대적으로 빠르다. -
넓은 의존성: 하나의 부모 RDD가 여러 자식 RDD에 걸쳐서 의존하는 경우이다. 예를 들어,
groupByKey나reduceByKey와 같은 연산은 넓은 의존성을 가진다. 이 경우, 데이터를 셔플(shuffle)해야 하므로 네트워크 통신이 발생하고, 연산 비용이 커진다.
메모리 부족 시 처리 방법
스파크는 기본적으로 데이터를 메모리에 저장해 처리하지만, 메모리가 부족할 경우 스파크는 데이터를 디스크로 저장해 처리한다. 이로 인해 성능 저하가 발생할 수 있지만, 스파크는 데이터 파티셔닝과 스토리지 레벨 조정을 통해 메모리 사용을 최적화할 수 있다. 또한, LRU(Least Recently Used) 방식으로 덜 사용된 데이터를 우선적으로 디스크로 내보내 메모리를 확보한다.
장애 복구 방식
RDD는 각 변환의 계보(lineage)를 기록함으로써 내결함성을 제공한다. 만약 노드 장애가 발생해 일부 데이터를 잃게 되더라도, RDD는 계보를 따라 변환 과정을 다시 실행해 데이터를 복구할 수 있다. 이는 데이터를 별도로 복제하지 않고도 복구할 수 있는 효과적인 방법이다.
Leave a comment