실시간 대용량 데이터 파이프라인 구축 : V2X 프로젝트
About
프로젝트 개요
- 실시간으로 생성되는 대용량 데이터를 저장하고, 데이터 레이크를 기반으로 한 분석 환경을 제공하기 위한 파이프라인 구축
프로젝트 규모 및 일정
- 팀원 : 5명
- 기간 : 07.23 ~ 08.06
역할
• 파이프라인 설계 • Spark 클러스터 구축 • Data Lake 설계 • 일일 데이터 대시보드 구축
Architecture
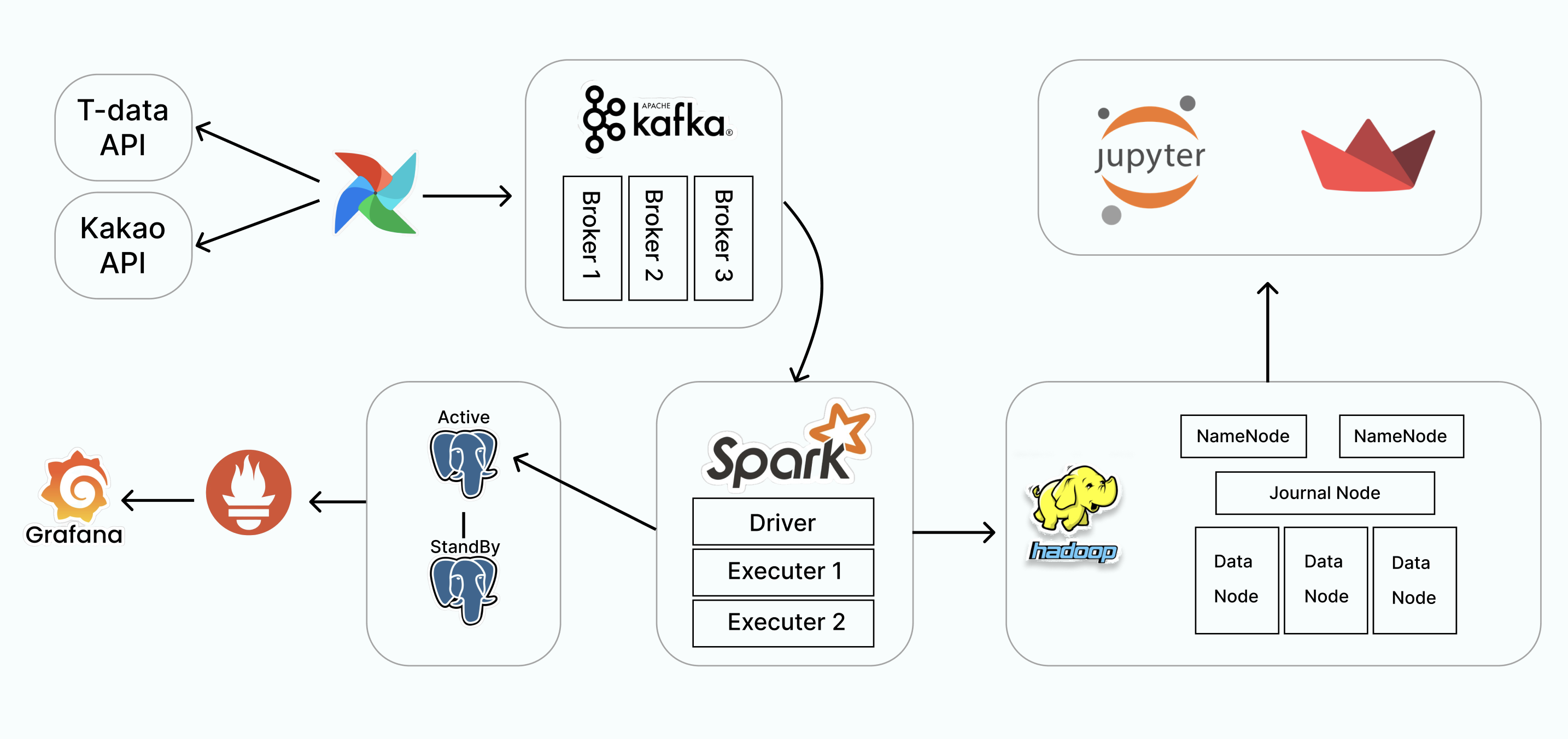
개요
1. 파이프라인
-
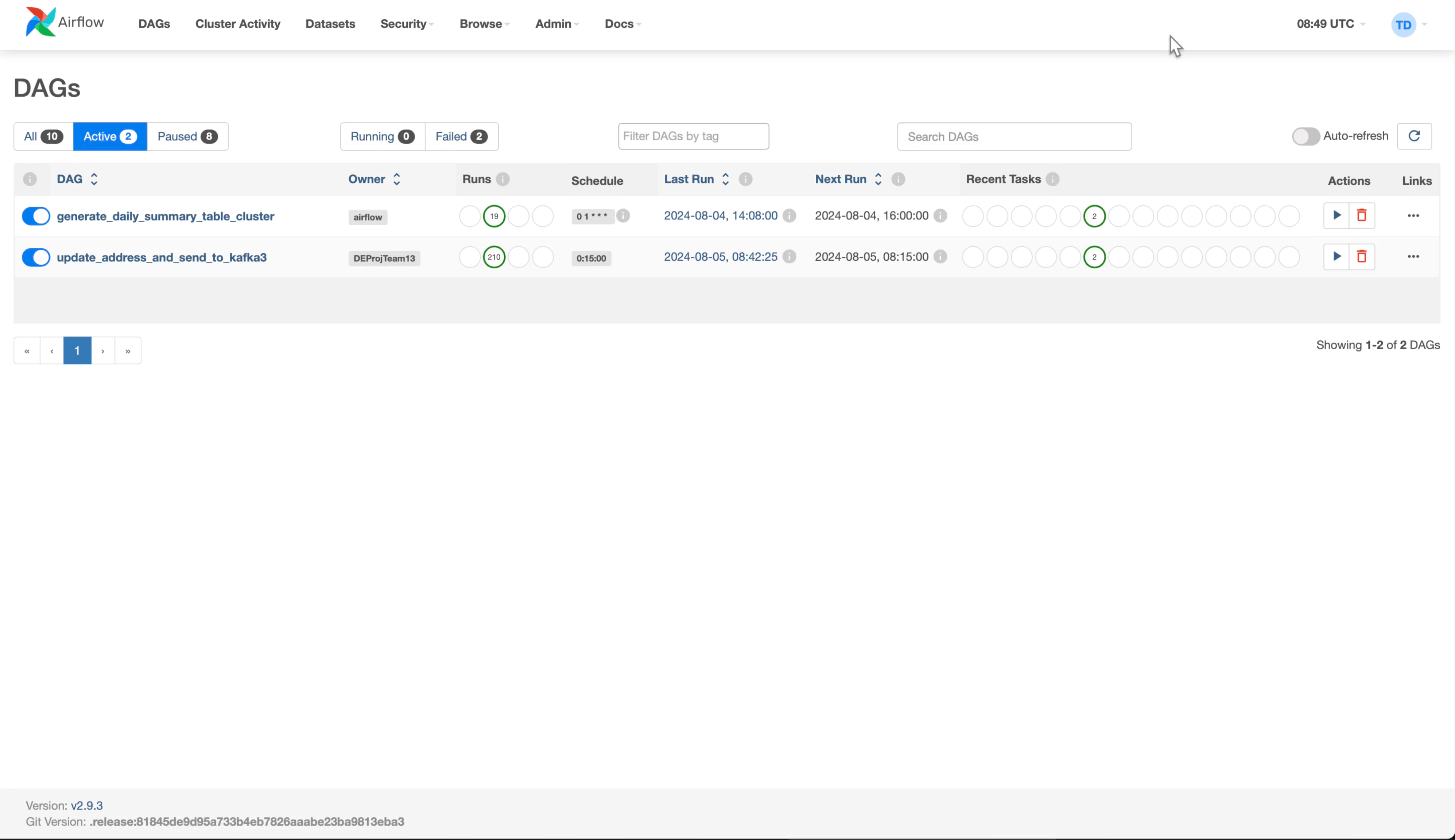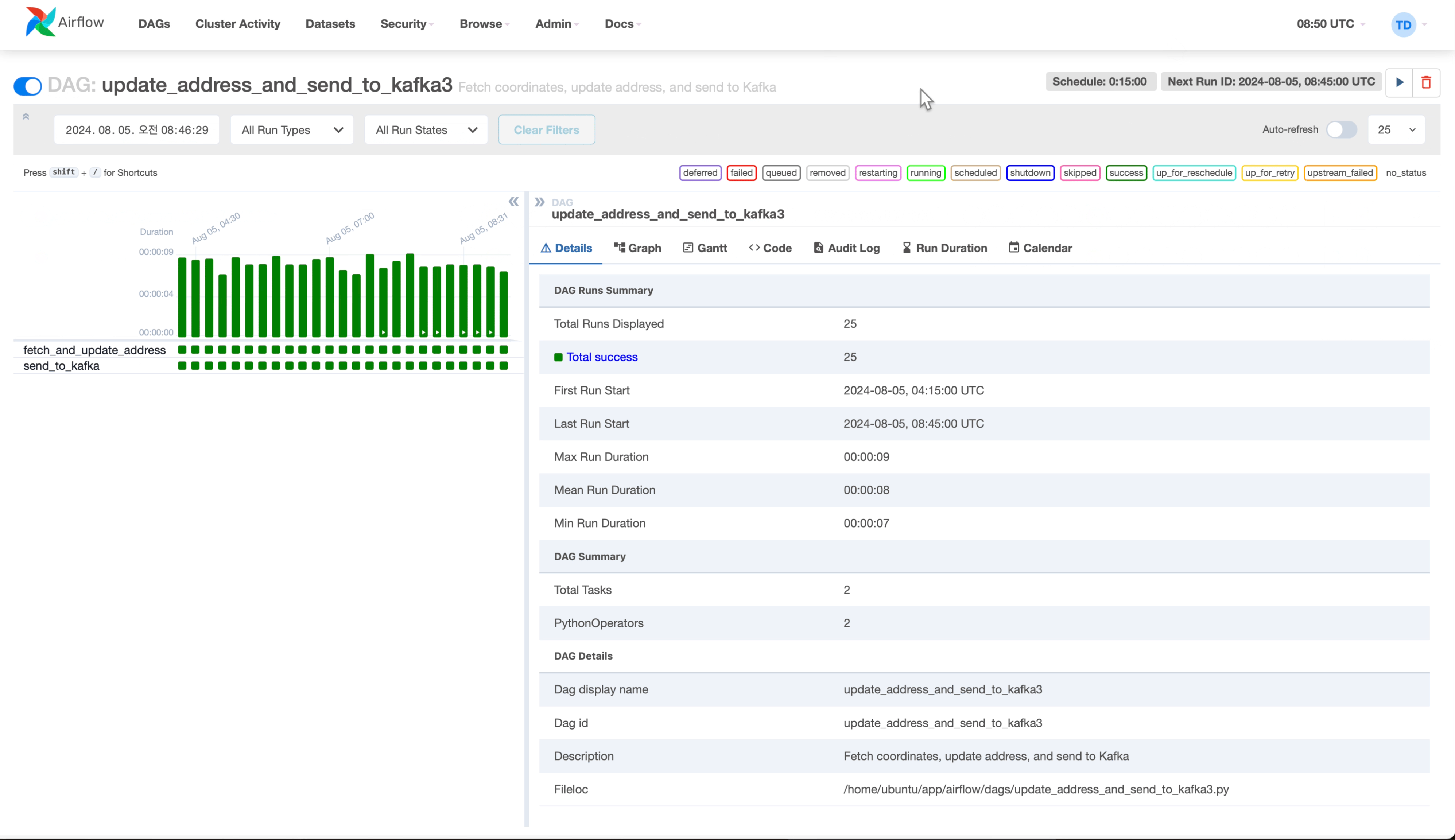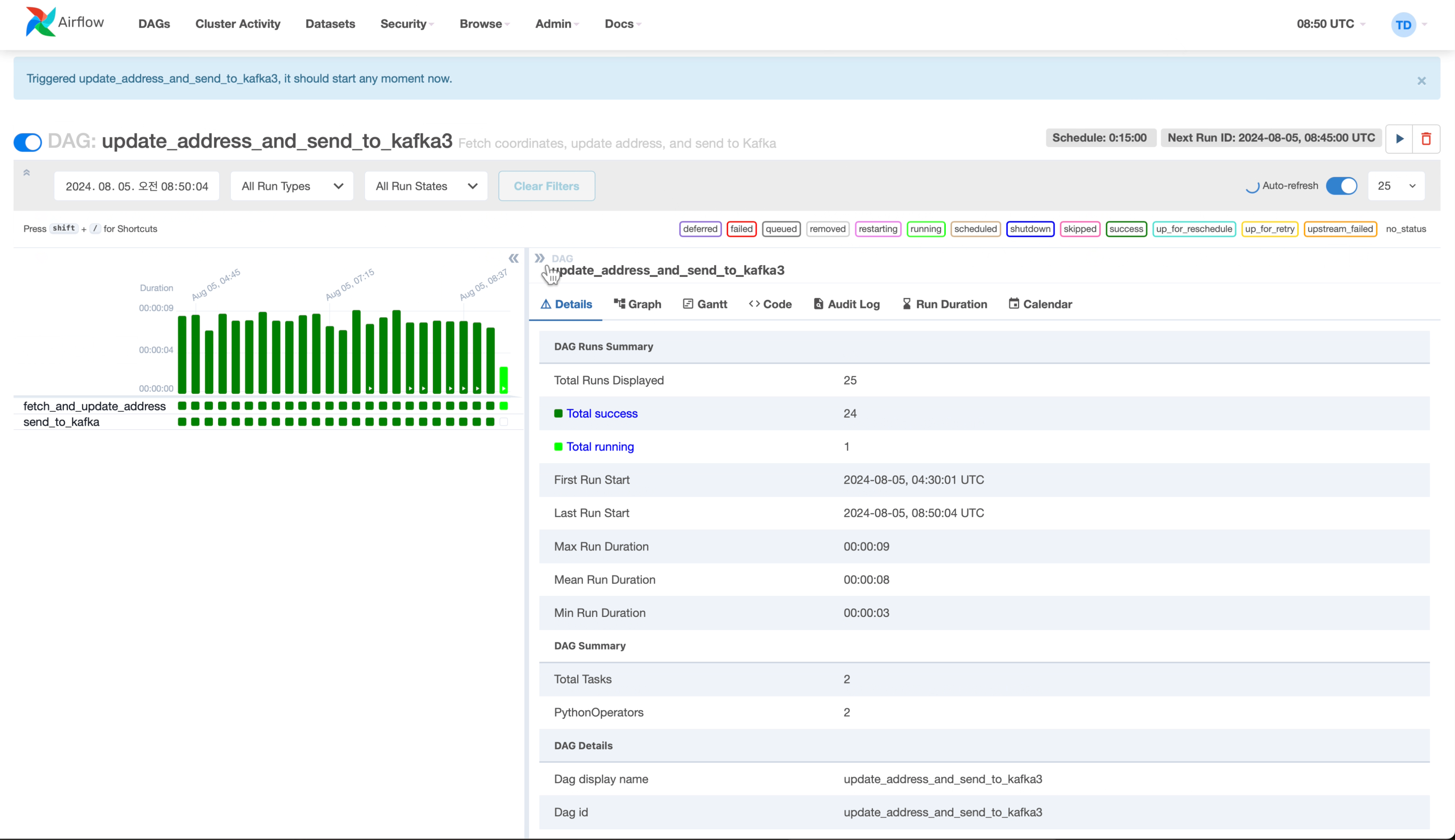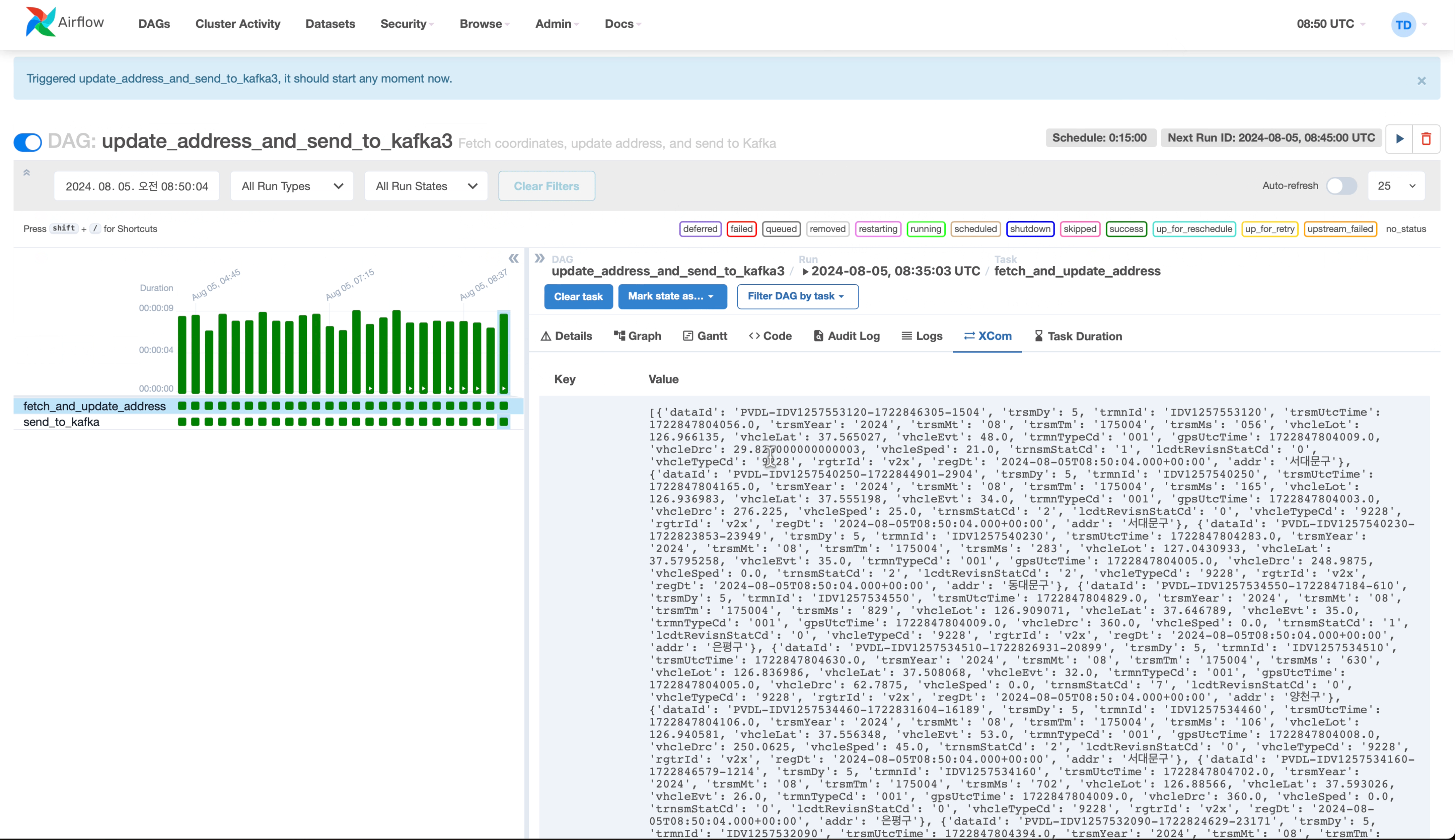
Airflow DAG 구성
- T-data API에서 차량 위치 데이터를 수집하고, Kakao API를 사용해 수집된 위치의 주소 정보를 획득.
- 비동기 구성을 통해 실시간 대용량 데이터 수집 및 파이프라인 작업 지원.
-
Kafka 클러스터 및 데이터 전송
- 브로커 3개로 구성된 Kafka 클러스터를 구축.
- Airflow에서 받은 데이터를 Kafka 토픽으로 전송하고 Spark 클러스터로 데이터를 consume해 실시간 처리.
-
Spark 스트림 애플리케이션
- Spark로 실시간 데이터를 처리하기 위한 스트림 애플리케이션 생성.
- 처리된 데이터를 Parquet 형식으로 변환해 저장.
-
데이터 저장 및 고가용성 구성
- Kafka 스트림 데이터를 PostgreSQL과 Hadoop HDFS에 저장.
- PostgreSQL: Streaming replication 방식을 사용해 master-slave 이중화 구성.
- Hadoop HDFS: 2대의 네임노드, 3대의 저널노드와 데이터 노드로 고가용성 유지.
2. 데이터 분석환경 구축 및 대시보드 구현
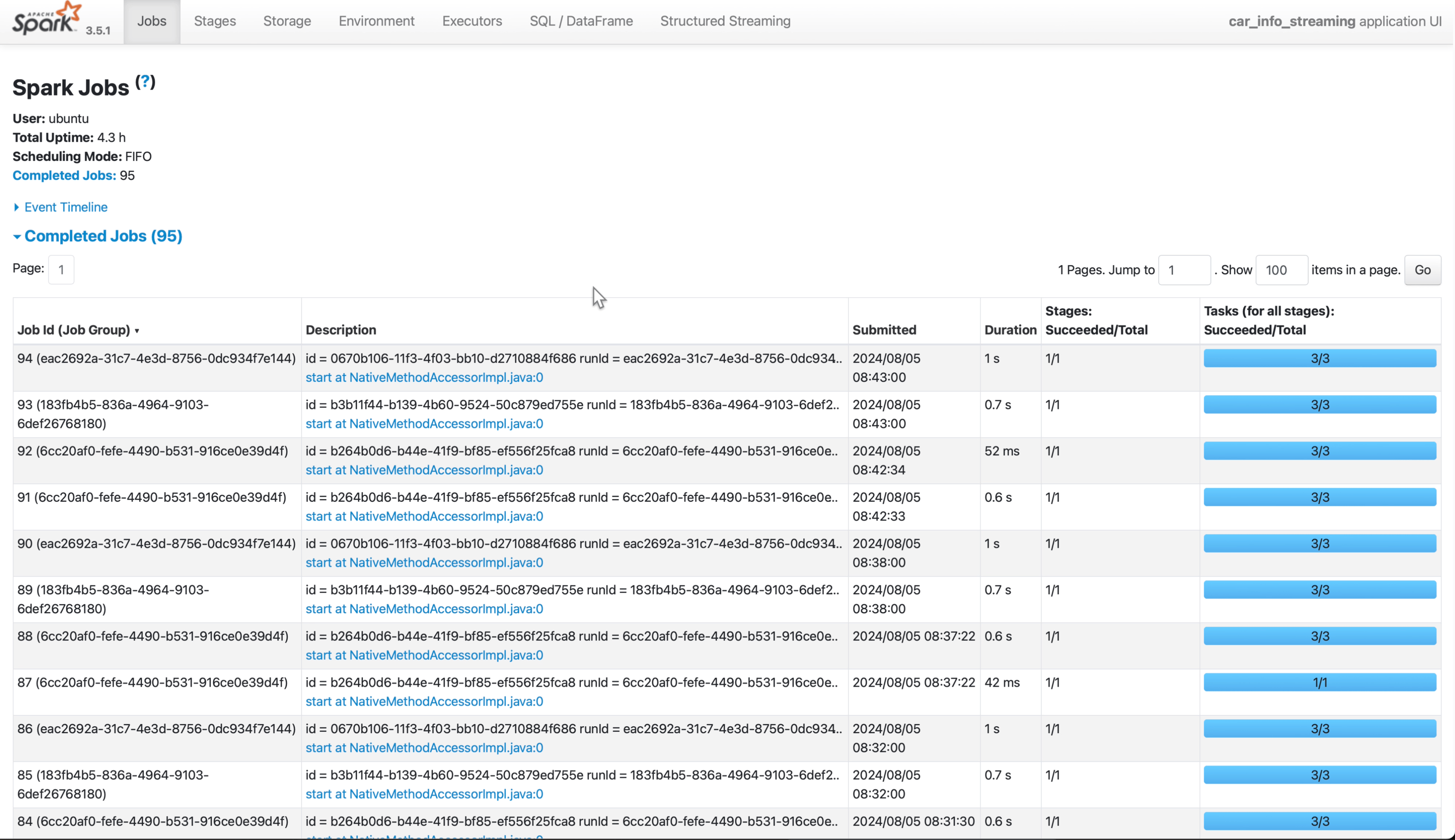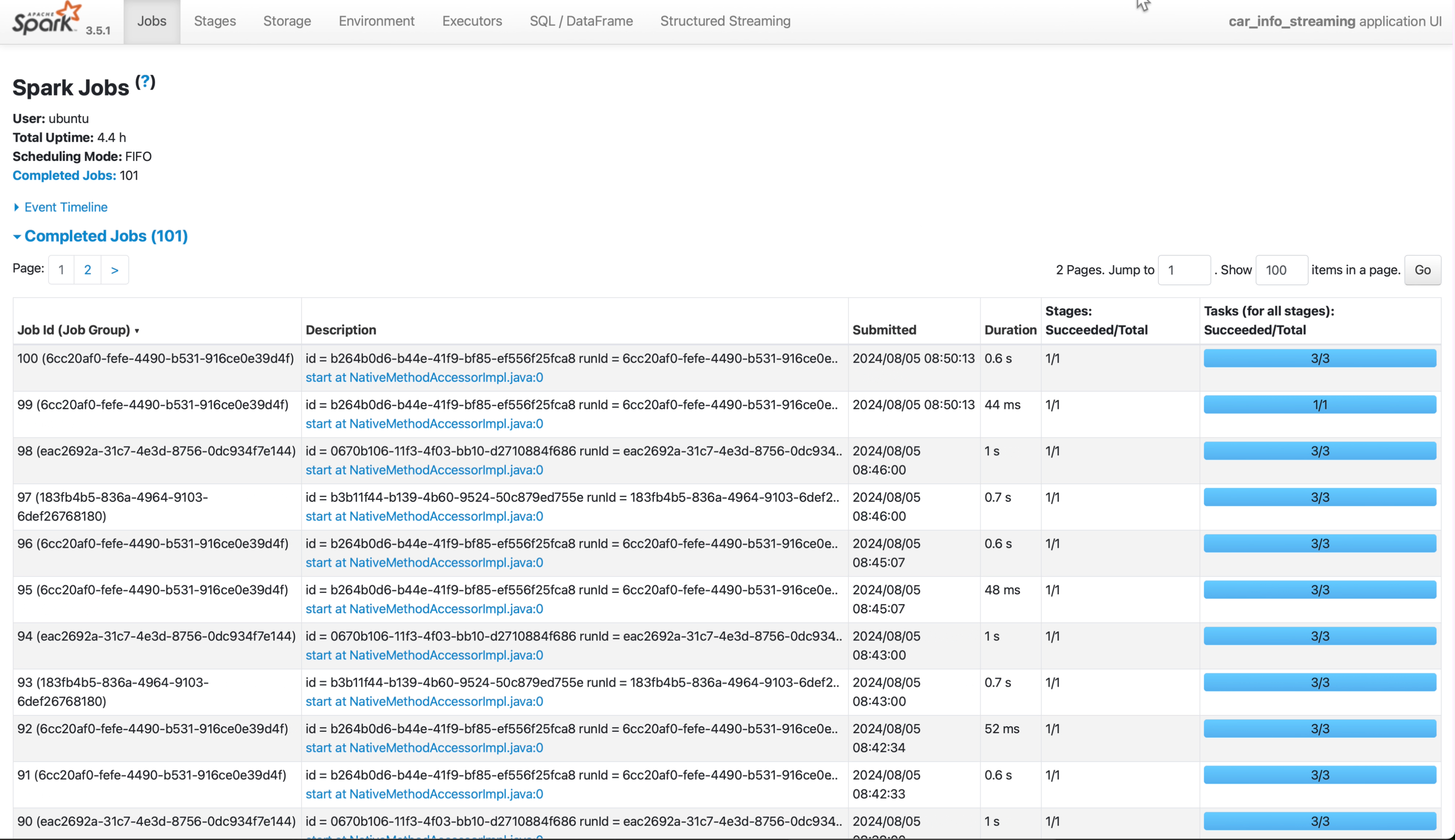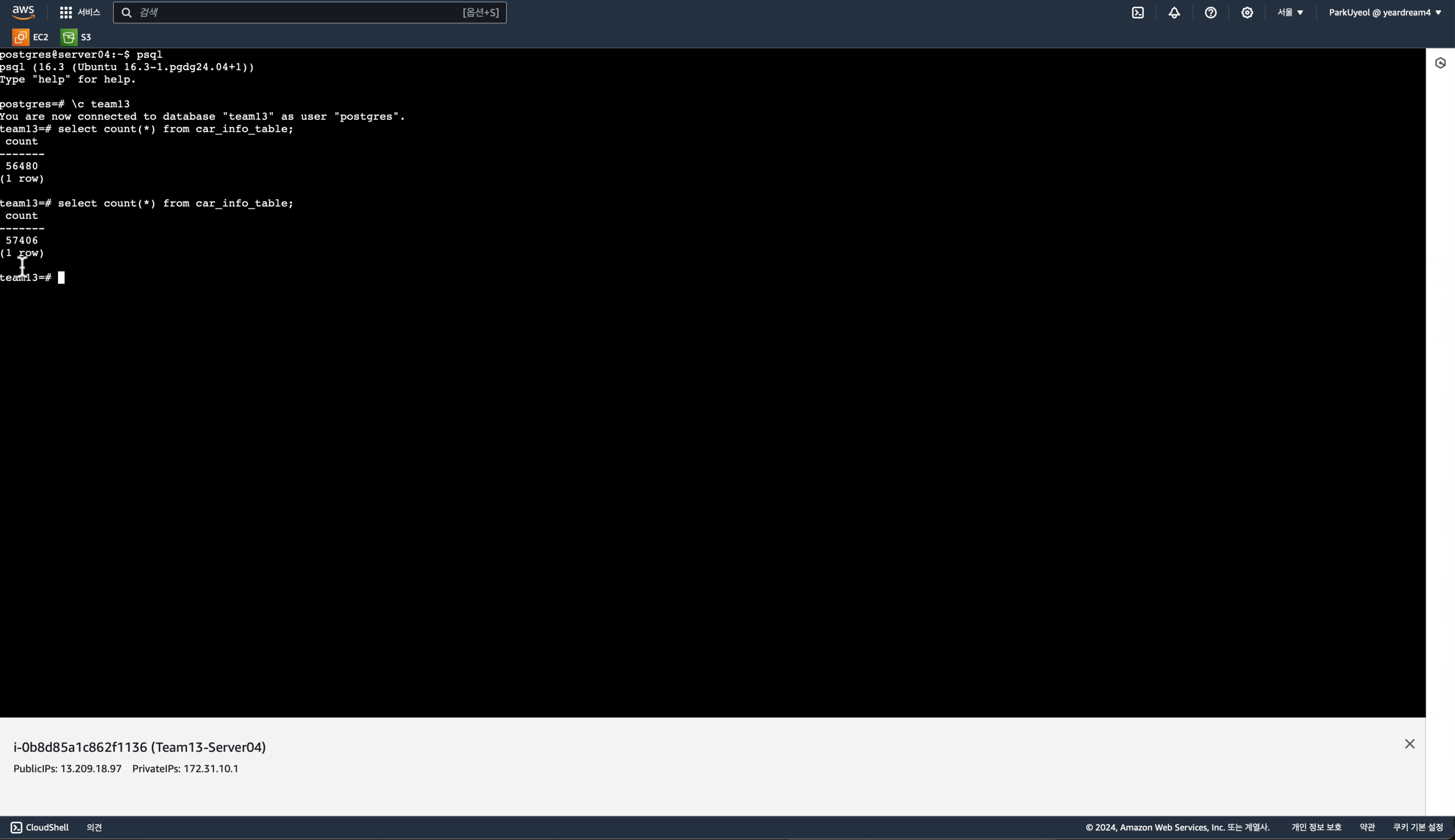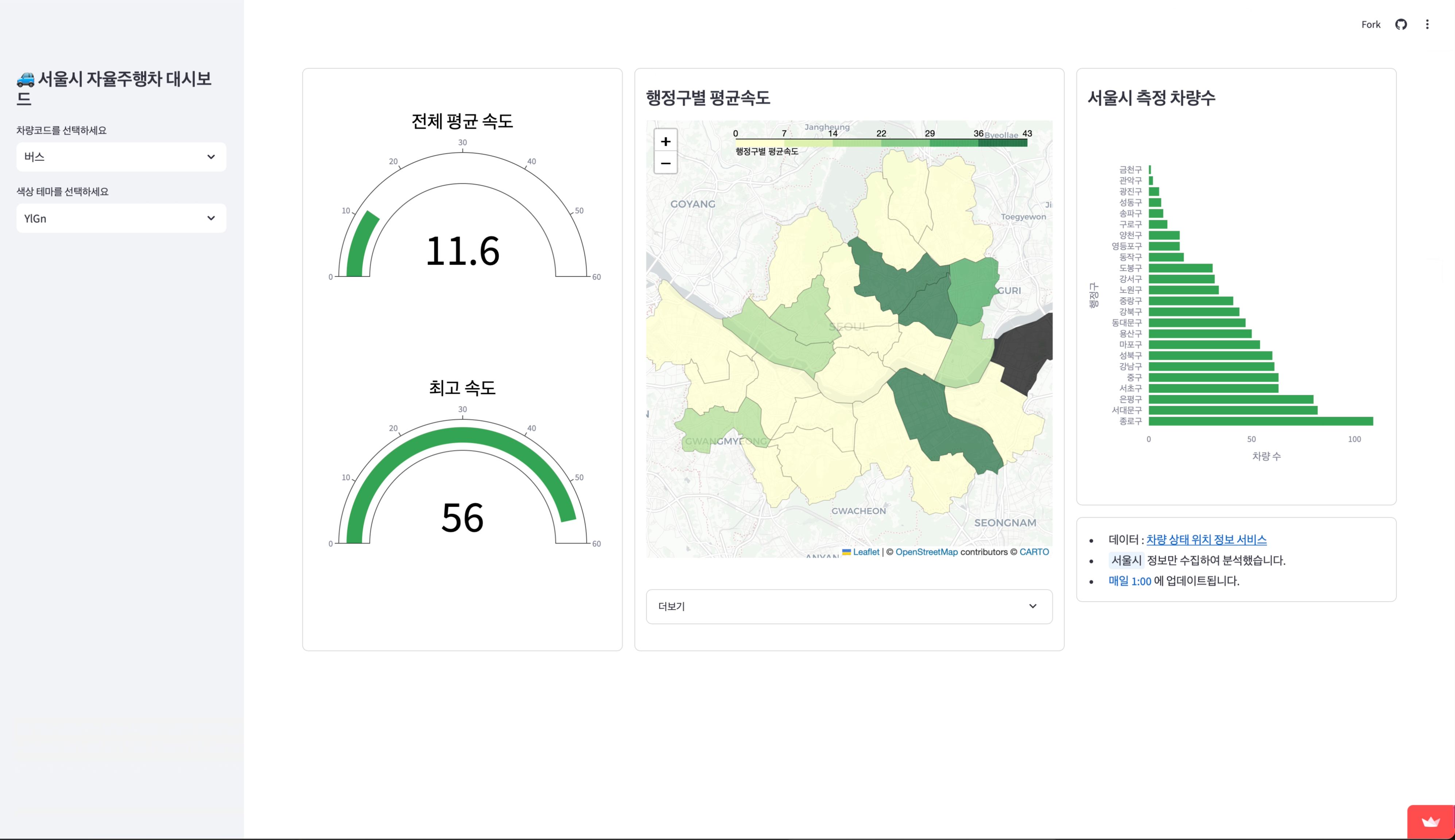
- 데이터 웨어하우스 및 분석팀 지원
- Hadoop HDFS에 저장된 데이터는 데이터 분석을 위한 데이터 웨어하우스에 활용.
- Parquet 파일을 CSV 파일로 변환해 일자별 데이터 레이크를 구축하고 간단한 일자별 대시보드를 제작하여 시각화.
3. 모니터링
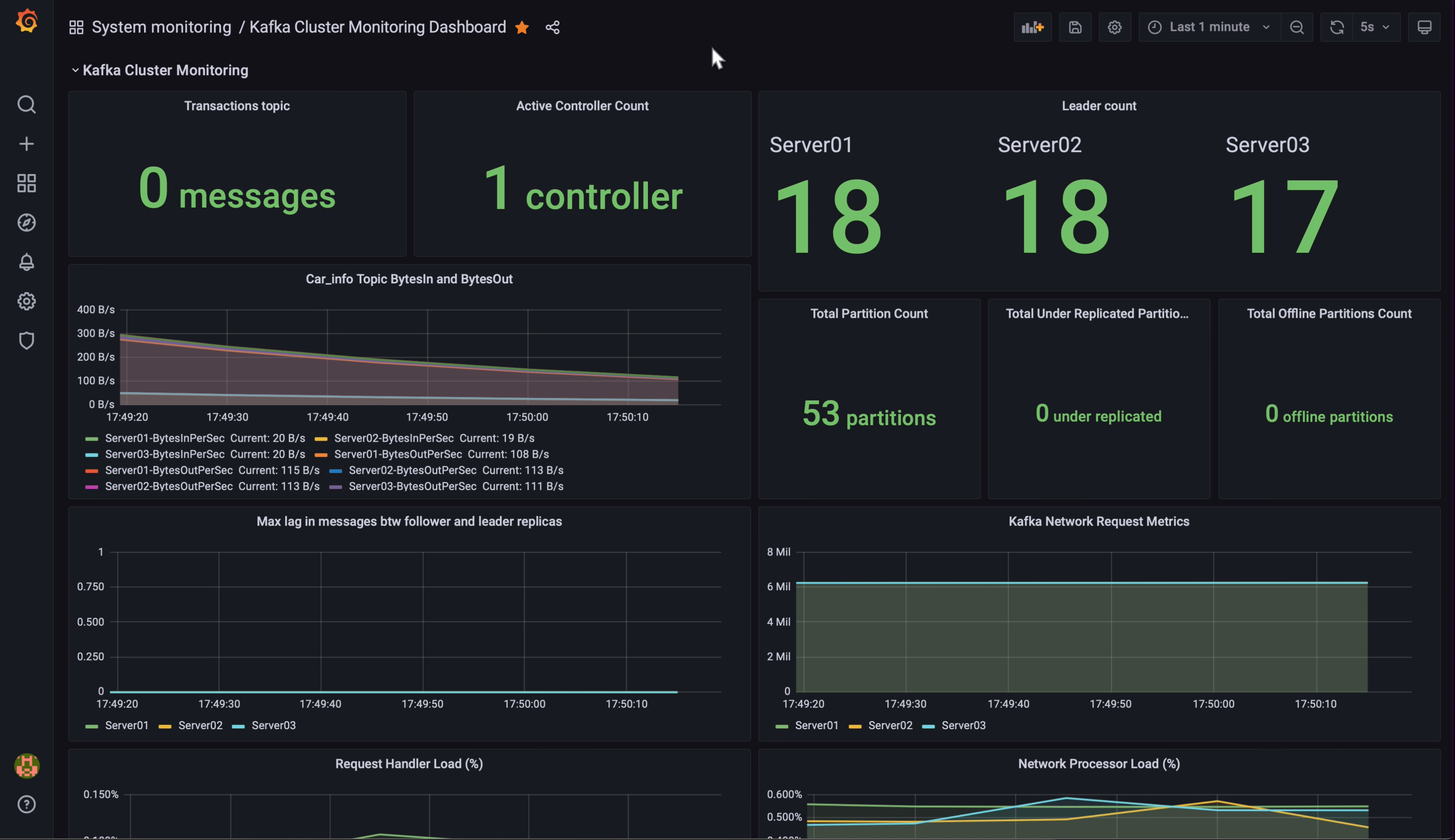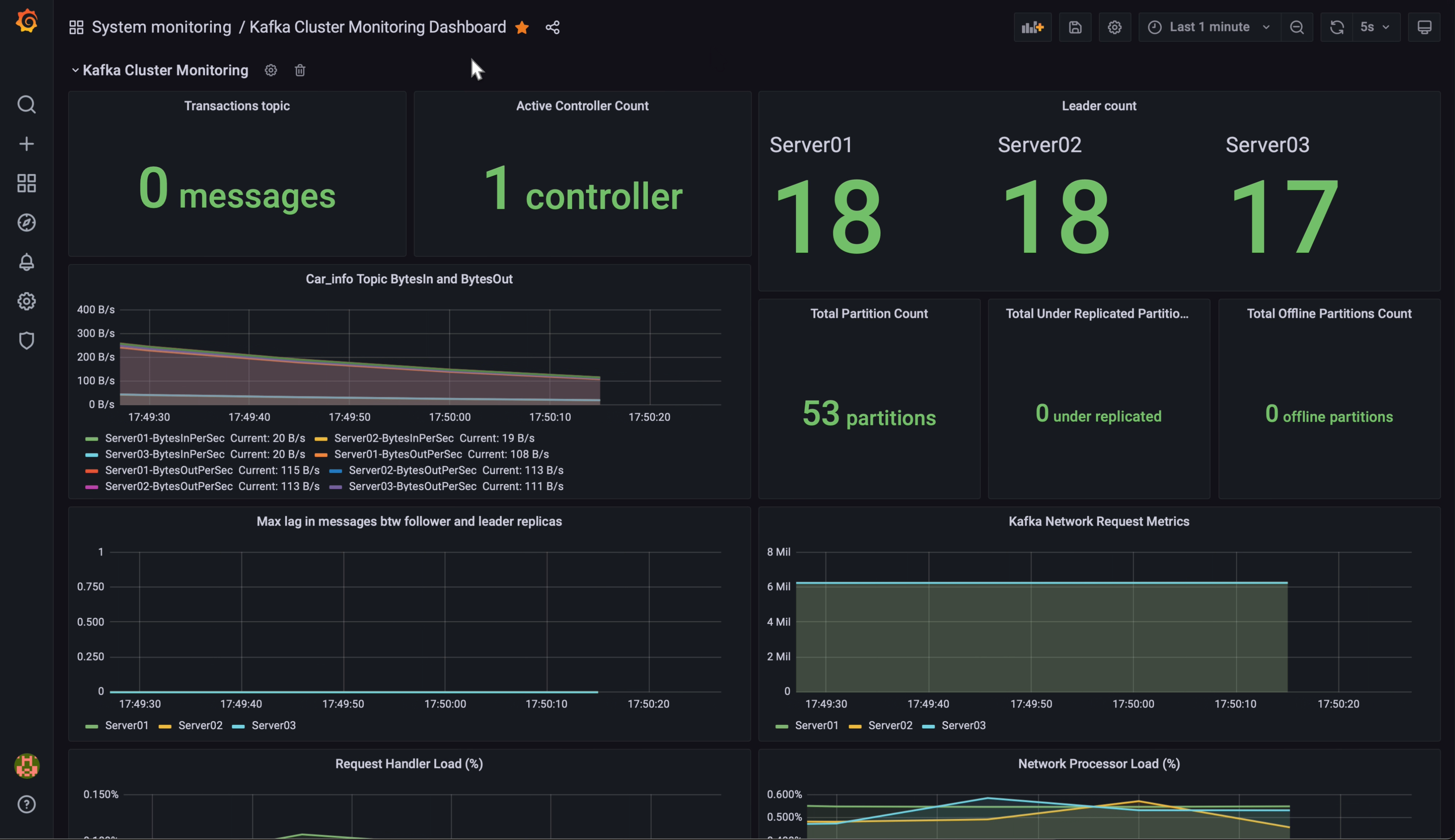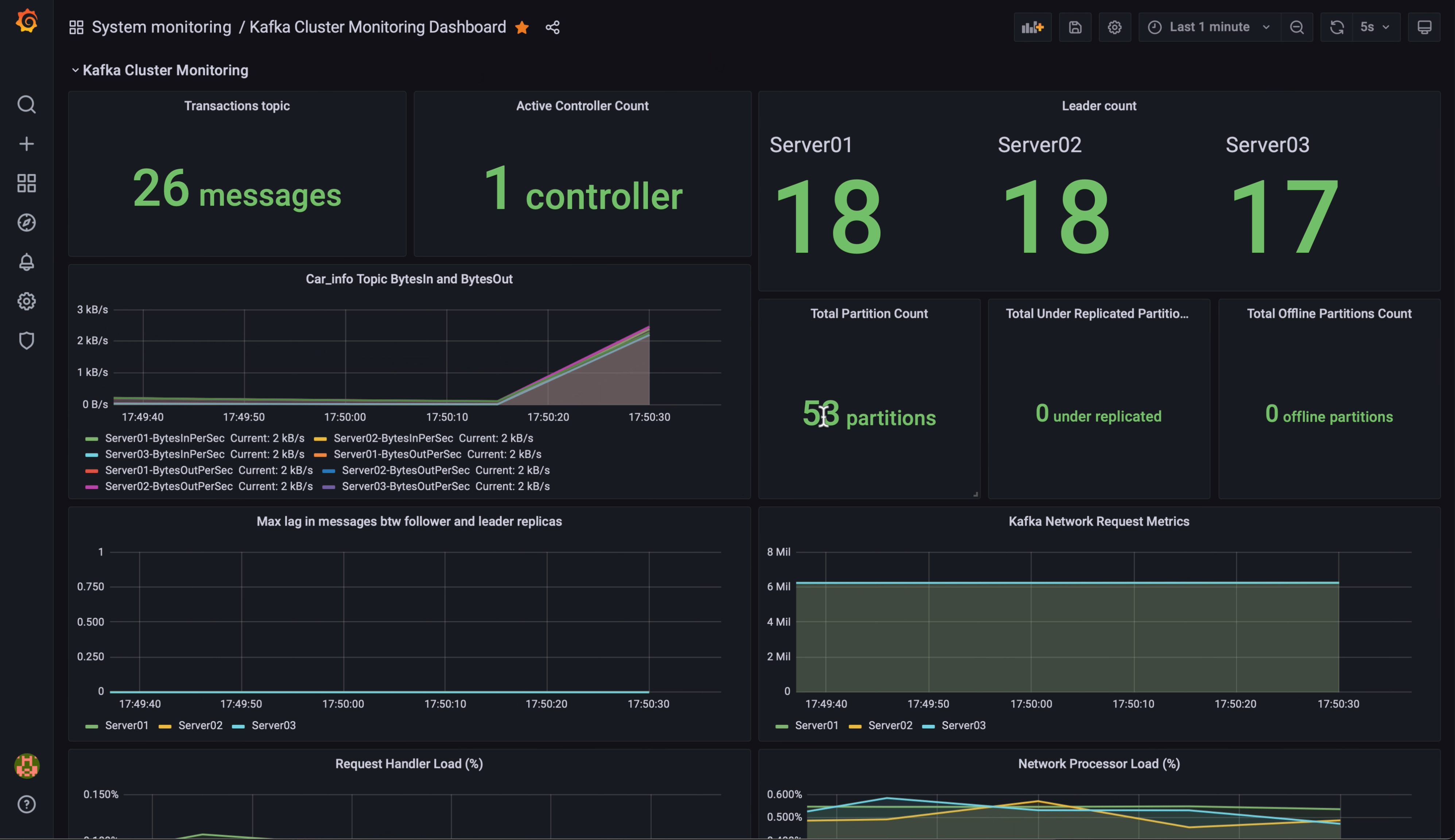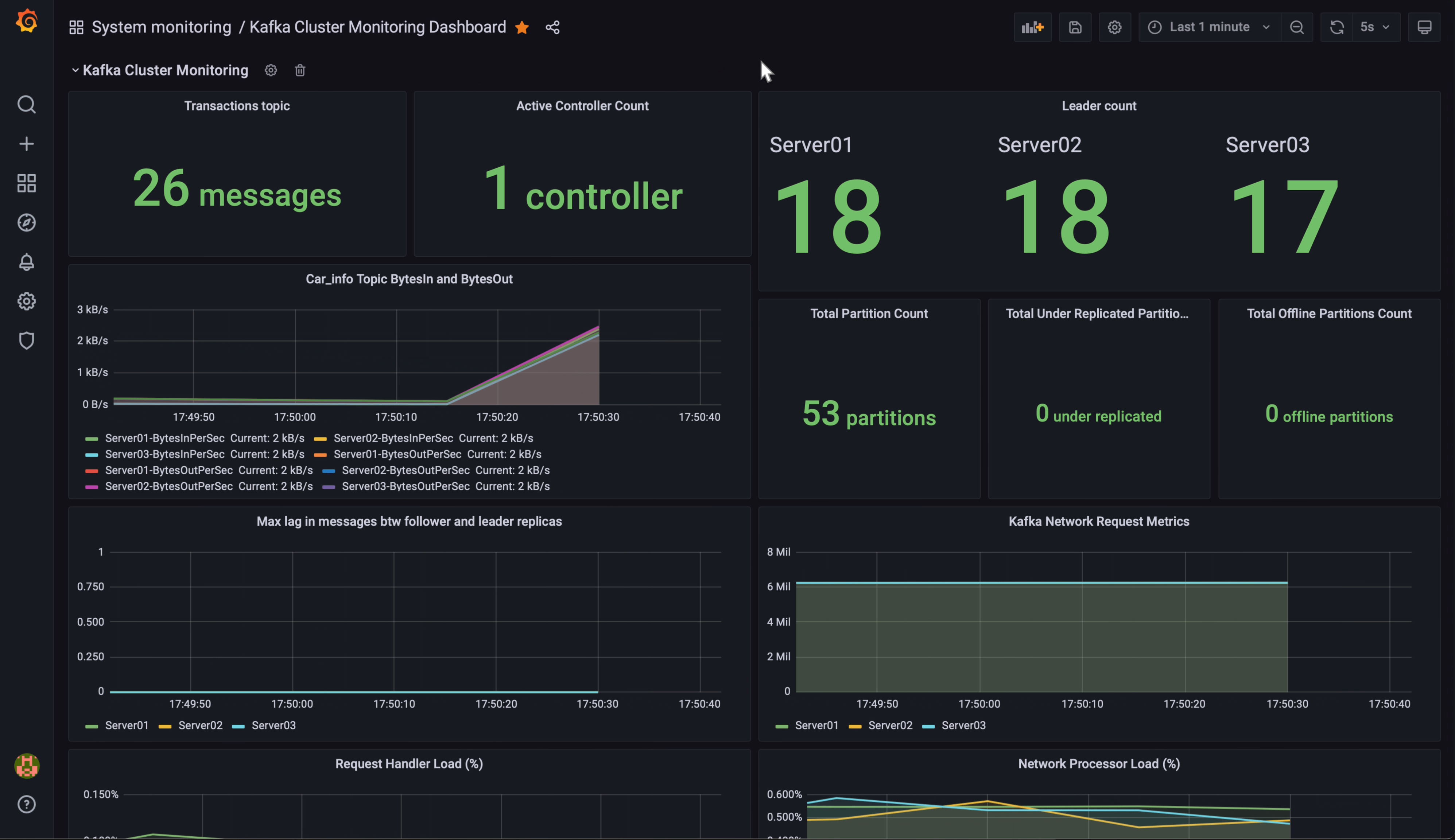
- 모니터링 시스템 구축
- Prometheus로 PostgreSQL을 모니터링하기 위해 JMX Exporter를 설치해 Prometheus 형식으로 메트릭 변환.
- Grafana 대시보드를 통해 엔지니어링 팀이 파이프라인 상태를 실시간으로 모니터링 가능.